



Using open-source datasets is crucial for developing and testing computer vision models. Here are 10 notable datasets that cover a wide range of computer vision tasks, including object detection, image classification, segmentation, and more.
Common Objects in Context (COCO)
Description: The Common Objects in Context (COCO) dataset is a large-scale dataset that includes such objects as cars, bicycles, and animals, as well as more specific categories such as umbrellas, handbags, and sports equipment. It was created to overcome the limitations of existing datasets by including more contextual details, a broader range of object categories, and more instances per category.
COCO dataset is commonly used for several computer vision tasks, including but not limited to object detection, semantic segmentation, superpixel stuff segmentation, keypoint detection, and image captioning (5 captions per image). Its diverse range of images and annotations includes 330K images (>200K labeled), 1.5 million object instances, 80 object categories, and 250,000 people with keypoints.
Be aware that although COCO annotations are famous and widely used, their quality can vary and sometimes may be restrictive for certain use cases.
History: The COCO dataset was first introduced in 2014 to improve the state of object recognition technologies. While the dataset itself has not been updated regularly in terms of new images being added, its annotations and capabilities are frequently enhanced and expanded through challenges and competitions held annually.
Licensing: The COCO dataset is released under the Creative Commons Attribution 4.0 License, which allows both academic and commercial use with proper attribution.
Official Site: https://cocodataset.org/

ImageNet
Description: ImageNet is a collection of images structured around the WordNet classification system. WordNet groups each significant idea, which might be expressed through various words or phrases, into units known as "synonym sets" or "synsets." With over 100,000 synsets, predominantly nouns exceeding 80,000, ImageNet's goal is to furnish roughly 1000 images for every synset to accurately represent each concept. The images for each idea undergo strict quality checks and are annotated by humans for accuracy. Upon completion, ImageNet aspires to present tens of millions of meticulously labeled and organized images, covering the breadth of concepts outlined in the WordNet system.
ImageNet played a pivotal role in the evolution of computer vision technologies, particularly through the annual ImageNet Large Scale Visual Recognition Challenge (ILSVRC), which has been important in pushing the boundaries of image recognition capabilities and deep learning techniques. It is widely recognized for its role in advancing machine learning and computer vision, particularly in areas such as object recognition, image classification, and deep learning research.
History: The ImageNet project, initiated in 2009 by researchers at Stanford University, was designed to create a vast database of labeled images to enhance the field of computer vision. ImageNet significantly influenced the growth of deep learning, especially through its yearly ImageNet Large Scale Visual Recognition Challenge, which was held until 2017. Although these challenges have ended, the ImageNet dataset remains a key resource in the computer vision field, even though it is not regularly updated with new images.
Licensing: ImageNet does not own the copyright of the images, it only compiles an accurate list of web images for each synset of WordNet. For this reason, ImageNet is available for use under terms that facilitate both academic and non-commercial research, with specific guidelines for usage and attribution.
Official Site: https://www.image-net.org/

PASCAL VOC
Description: PASCAL VOC is a well known dataset and benchmarking initiative designed to promote progress in visual object recognition. It offers a substantial dataset and tools for research and evaluation on its dedicated platform, serving as an essential resource for the computer vision community.
The PASCAL VOC dataset was developed to offer a diverse collection of images that reflect the complexity and variety of the world, which is crucial for building more effective object recognition models. This dataset has become a cornerstone in the field of computer vision, driving significant advancements in image classification technologies. The challenges associated with PASCAL VOC played an important role in pushing researchers to improve the accuracy, efficiency, and reliability of computerized image understanding and categorization. PASCAL VOC's dataset played a huge role in such fields as instance segmentation, image classification, person pose estimation, object detection, and person action classification
History: The PASCAL VOC project, initiated in 2005, was developed to offer a standard dataset for tasks related to image recognition and object detection. It gained recognition through its yearly challenges that significantly advanced the field until they concluded in 2012. Although these annual challenges have ended, the PASCAL VOC dataset remains an important tool for researchers in computer vision, even though it is not updated with new data anymore.
Licensing: PASCAL VOC is made available under conditions that support academic and research-focused projects, adhering to guidelines that encourage the ethical and responsible use of the dataset. Also, the VOC data includes images obtained from the "flickr" website, for more information, see "flickr" terms of use.
Official Site: http://host.robots.ox.ac.uk/pascal/VOC

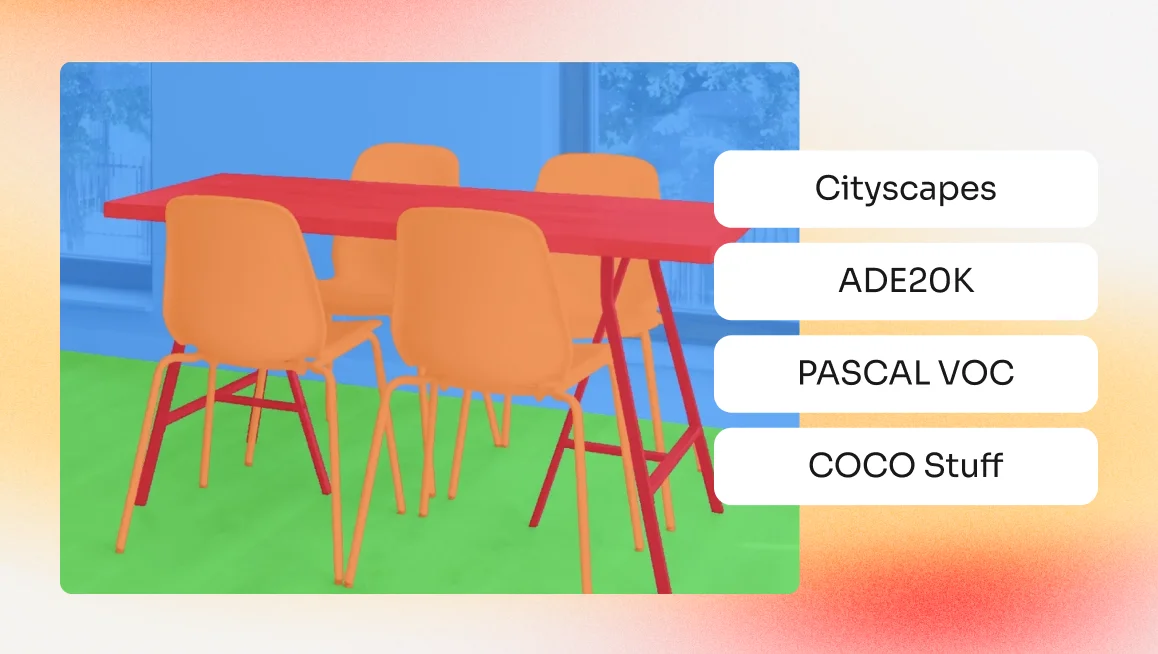
Cityscapes
Description: The Cityscapes dataset was created to help improve how we understand and analyze city scenes visually. This dataset includes a varied collection of stereo video sequences captured across street scenes in 50 distinct cities. It boasts high-quality, pixel-precise annotations for 5,000 frames and also includes an extensive selection of 20,000 frames with basic annotations. Consequently, Cityscapes significantly surpasses the scale of earlier projects in this domain, offering an unparalleled resource for researchers and developers focusing on urban environment visualization.
Cityscapes was developed with the ambition to close the gap in the availability of an urban-focused dataset that could drive the next leap in autonomous vehicle technology and urban scene analysis. Cityscapes offers a rich collection of annotated images focused on semantic urban scene understanding. This initiative has catalyzed significant advancements in the analysis of complex urban scenes, contributing to the development of algorithms capable of more nuanced understanding and interaction with urban environments.
History: The Cityscapes dataset was launched around 2019 to aid research aimed at understanding urban scenes at a detailed level, especially for segmentation tasks that require precise pixel and object identification. This dataset is regularly updated and remains crucial in the field, assisting developers and researchers in enhancing systems like those used in autonomous vehicles.
Licensing: The Cityscapes dataset is provided for academic and non-commercial research purposes.
Official Site: https://www.cityscapes-dataset.com/

KITTI
Description: The KITTI dataset is well-known in the field of autonomous driving research, offering a comprehensive suite for several computer vision tasks related to automotive technologies. The dataset is focused on real-world scenarios and encompasses several key areas: stereo vision, optical flow, visual odometry, and 3D object detection and 3D object tracking.
Developed to bridge the gap in automotive vision datasets, KITTI was developed to improve the domain of autonomous driving by providing a dataset that captures the complexity of real-world driving conditions with a depth and variety unseen in previous collections.
History: The KITTI dataset was launched in 2012 to help advance autonomous driving technologies, concentrating on specific tasks such as stereo vision, optical flow, visual odometry, 3D object detection, and tracking. It was developed through a partnership between the Karlsruhe Institute of Technology and the Toyota Technological Institute at Chicago. While the KITTI dataset is not updated regularly, it remains an essential tool for researchers and developers in the automotive technology field.
Licensing: The KITTI dataset is made available under a Creative Commons Attribution-NonCommercial-ShareAlike 3.0 License that supports academic research and technological development, promoting its use among scholars and developers in the autonomous driving community.
Official Site: https://www.cvlibs.net/datasets/kitti

VGGFace2
Description: VGGFace2 is made of around 3.31 million images divided into 9131 classes, each representing a different person identity. It is used for a multitude of computer vision tasks such as face detection, face recognition, and landmark localization. It boasts a rich collection of images featuring a wide demographic diversity, including variations in age, pose, lighting, ethnicity, and profession, thus ensuring a robust framework for developing and testing algorithms that closely mimic human-level understanding of faces.
The dataset comprises images of faces ranging from well-known public figures to individuals across various walks of life, enhancing the depth and applicability of face recognition technologies in real-world scenarios.
History: VGGFace2 developed by researchers from the Visual Geometry Group at the University of Oxford was introduced in 2017 as an extension of the original VGGFace dataset. There are no regular updates to the VGGFace2 as it was released as a static collection for academic research and development purposes.
Licensing: VGGFace2 supports both academic research and non-commercial use, detailed on its website.
Official Website: https://paperswithcode.com/dataset/vggface2-1

CIFAR-10 & CIFAR-100
Description: The CIFAR-10 and CIFAR-100 datasets are curated segments of the extensive 80 million tiny images collection, put together by researchers Alex Krizhevsky, Vinod Nair, and Geoffrey Hinton. These datasets were created to facilitate the analysis of real-world imagery. CIFAR-10 encompasses 60,000 color images of 32x32 pixels each, distributed across 10 categories, with each category featuring 6,000 images. This dataset is split into 50,000 images for training and 10,000 for testing, spanning a diverse array of subjects such as animals and vehicles.
On the other hand, CIFAR-100 expands on this by offering 100 categories, each with 600 images, making for a total of the same 60,000 images but with a finer division. It allocates 500 images for training and 100 images for testing in each category. The CIFAR-100 dataset further organizes its categories into 20 supercategories, with each image tagged with both a "fine" label, identifying its specific category, and a "coarse" label, denoting its supercategory grouping.
These datasets were created to push forward the study of image recognition by offering a detailed and varied collection of images that previous datasets lacked. They aid in developing algorithms that can distinguish and recognize a broad array of object types, bringing computer vision closer to human-like understanding.
History: CIFAR-10 and CIFAR-100 were developed by researchers at the University of Toronto and released around 2009. They have not been regularly updated since their release, serving primarily as benchmarks in the academic community.
Licensing: Both CIFAR-10 and CIFAR-100 are freely available for academic and educational use, under a license that supports their wide use in research and development within the field of image recognition (licensing information can be found on the official site).
Official Site: https://www.cs.toronto.edu/~kriz/cifar.html

IMDB-WIKI
Description: To address the constraints of small to medium-sized, publicly available face image datasets, which often lack comprehensive age data and rarely contain more than a few tens of thousands of images, the IMDB-WIKI dataset was developed. Utilizing the IMDb website, the creators selected the top 100,000 actors and methodically extracted their birth dates, names, genders, and all related images.
In a similar vein, profile images and the same metadata were collected from Wikipedia pages. Assuming images with a single face likely depict the actor, and by trusting the accuracy of the timestamps and birth dates, a real biological age was assigned to each image. Consequently, the IMDB-WIKI dataset comprises 460,723 face images from 20,284 celebrities listed on IMDb, along with an additional 62,328 images from Wikipedia, bringing the total to 523,051 images suitable for use in facial recognition training.
History: The IMDB-WIKI was created by researchers at ETH Zurich in 2015. It has not received regular updates since its initial release.
Licensing: The MDB-WIKI dataset can be used only for non-commercial and research purposes (licensing information can be found on the official site).
Official Site: https://data.vision.ee.ethz.ch/cvl/rrothe/imdb-wiki/

Open Images Dataset by Google
Description: The Open Images Dataset by Google is recognized as one of the largest and most detailed public image datasets available today. It is designed to support the wide variety of requirements that come with computer vision applications. Covering a vast range of categories, from simple everyday items to intricate scenes and activities, this dataset strives to exceed the boundaries of previous collections by offering an extensive array of detailed annotations for a broad spectrum of subjects.
Integral to a host of computer vision tasks, including image classification, object detection, visual relationship detection, and instance segmentation, the Open Images Dataset is a treasure trove for advancing machine learning models.
Diving into specifics, the dataset includes:
- 15,851,536 bounding boxes across 600 object classes,
- 2,785,498 instance segmentations in 350 classes,
- 3,284,280 annotations detailing 1,466 types of relationships,
- 675,155 localized narratives that offer rich, descriptive insights,
- 66,391,027 point-level annotations over 5,827 classes, showcasing the dataset's depth in granularity,
- 61,404,966 image-level labels spanning 20,638 classes, highlighting the dataset's broad scope,
- An extension that further enriches the collection with 478,000 crowdsourced images categorized into over 6,000 classes.es
cription
History: The Open Images Dataset by Google was initially released in 2016. The dataset has been updated regularly, with its final version, V6, released in 2020, including enhanced annotations and expanded categories to further support the development of more accurate and diverse computer vision models.
Licensing: The annotations are licensed by Google LLC under CC BY 4.0 license. The images are listed as having a CC BY 2.0 license. Both licenses support academic research and commercial use, promoting its application across a wide array of projects and developments in the field of computer vision.
Official Site: https://storage.googleapis.com/openimages/web/index.html

SUN Database: Scene Categorization Benchmark
Description: The SUN dataset is a large and detailed collection created for identifying and categorizing different scenes. It is notable for its wide range of settings, from indoor spaces to outdoor areas, filling the need for more varied scene datasets as opposed to those focusing just on detection. The SUN Database aims to improve how we understand complicated scenes and their contexts by offering a wide variety of scene types and detailed annotations.
This dataset is crucial for many computer vision tasks, such as sorting scenes, analyzing scene layouts, and object detection in various settings. It includes over 130,000 images covering more than 900 types of scenes, each with careful annotations to help accurately recognize different scenes.
History: The SUN dataset was developed by researchers at Princeton University and Brown University and first released in 2010. Unlike some other datasets, the SUN Database has not been regularly updated since its initial release but remains a pivotal resource in the field of computer vision.
Licensing: The SUN Database is distributed under terms that permit academic research, provided there is proper attribution to the creators and the dataset itself.
Official site: https://vision.princeton.edu/projects/2010/SUN/

Conclusion
Concluding this article, we sincerely hope you found it helpful and that it enhances your research in model training and your daily computer vision tasks. If you haven't found exactly what you're looking for, please stay tuned and follow our social media channels. We plan to share our knowledge on how to create, annotate, and maintain your very own dataset tailored to your specific needs.
Stay curious, keep annotating!
Stay curious, keep annotating!
Not a CVAT.ai user? Click through and sign up here
Do not want to miss updates and news? Have any questions? Join our community:


.svg)
.png)

.png)









.png)