



Introduction
CVAT is a visual data annotation tool. Using it, you can take a set of images and mark them up with annotations that either classify each image as a whole, or locate specific objects on the image.
But let’s suppose you’ve already done that. What now?
Datasets are, of course, not annotated just for the fun of it. The eventual goal is to use them in machine learning, for either training an ML model, or evaluating its performance. And in order to do that, you have to get the annotations out of CVAT and into your machine learning framework.
Previously, the only way to do that was the following:
1. Export your CVAT project or task in one of the several dataset formats supported by CVAT.
2. Write code to read the annotations in the selected format and convert them into data structures suitable for your ML framework.
This approach is certainly workable, but it does have several drawbacks:
- The third-party dataset formats supported by CVAT cannot necessarily represent all information that CVAT datasets may contain. Therefore, some information can be lost when annotations are exported in such formats. For example, CVAT supports ellipse-shaped objects, while the COCO format does not. So when a dataset is exported into the COCO format, ellipses are converted into masks, and information about the shape is lost.
- Even when a format can store the necessary information, it may not be convenient to deal with. For example, in the COCO format, annotations are saved as JSON files. While it is easy to load a generic JSON file, data loaded in this way will not have static type information, so features like code completion and type checking will not be available.
- Dataset exporting can be a lengthy process, because the server has to convert all annotations (and images, if requested) into the new format. If the server is busy with other tasks, you may end up waiting a long time.
- If the dataset is updated on the server, you have to remember to re-export it. Otherwise, your ML pipeline will operate on stale data.
All of these problems stem from one fundamental source: the use of an intermediate representation. If we could somehow use data directly from the server, they would be eliminated.
So, in CVAT SDK 2.3.0, we introduced a new feature that will, for some use cases, implement exactly that. This feature is the cvat_sdk.pytorch module, also informally known as the PyTorch adapter. The functionality in this module allows you to directly use a CVAT project or task as a PyTorch-compatible dataset.
Let’s play with it and see how it works.
Setup
First, let’s create a Python environment and install CVAT SDK. To use the PyTorch adapter, we’ll install the SDK with the pytorch extra, which pulls PyTorch and torchvision as dependencies. We won’t be using GPUs, so we’ll get the CPU-only build of PyTorch to save download time.
$ python3 -mvenv ./venv
$ ./venv/bin/pip install -U pip
$ ./venv/bin/pip install 'cvat_sdk[pytorch]' \
--extra-index-url=https://download.pytorch.org/whl/cpu
$ . ./venv/bin/activate
Now we will need a dataset. Normally, you would use the PyTorch adapter with your own annotated dataset that you already have in CVAT, but for demonstration purposes we’ll use a small public dataset instead.
To follow along, you will need an account on the public CVAT instance, app.cvat.ai. If you have access to a private CVAT instance, you can use that instead. Save your CVAT credentials in environment variables so CVAT SDK can authenticate itself:
$ export CVAT_HOST=app.cvat.ai
$ export CVAT_USER='<your username>' CVAT_PASS
$ read -rs CVAT_PASS
<enter your password and hit Enter>
The dataset we’ll be using is the Flowers Dataset available in the Harvard Dataverse Repository. This dataset is in an ad-hoc format, so we won’t be able to directly import it into CVAT. Instead, we’ll upload it using a custom script. We won’t need the entire dataset for this demonstration, so the script will also reduce it to a small fraction.
Get that script from our blog repository and run it:
$ python3 upload-flowers.py
The script will create tasks for the train, test and validation subsets, and print their IDs. If you open the Tasks page, you will see that the tasks have indeed been created:
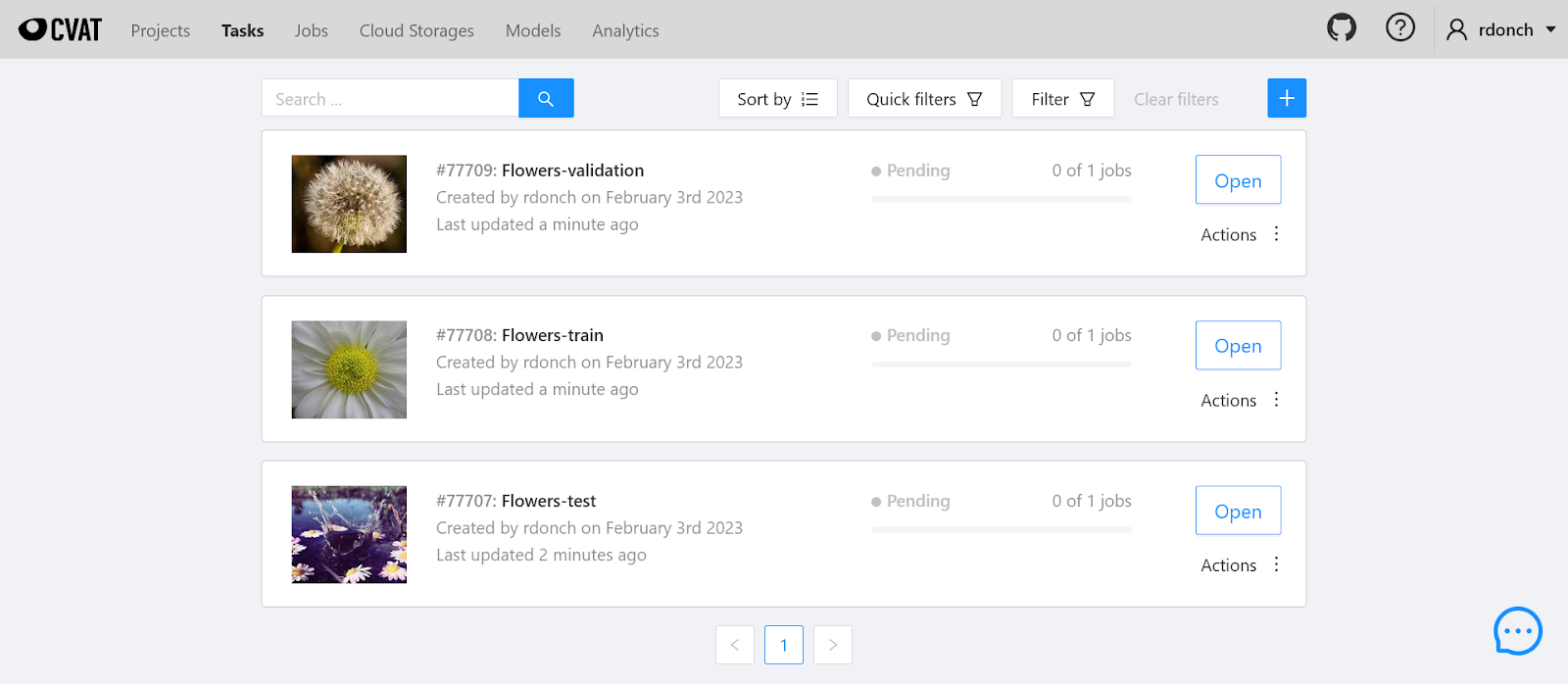
And if you open any of these tasks and click the “Job #XXXX” link near the bottom, you will see that each image has a single annotation associated with it: a tag representing the type of the flower.
.png)
Interactive usage
Note: the code snippets from this section are also available as a Jupyter Notebook.
We’re now ready to try the PyTorch adapter. Let’s start Python and create a CVAT API client:
$ python3
Python 3.10.6 (main, Nov 14 2022, 16:10:14) [GCC 11.3.0] on linux
Type "help", "copyright", "credits" or "license" for more information.
>>> import logging, os
>>> from cvat_sdk import *
>>> # configure logging to see what the SDK
>>> # is doing behind the scenes
>>> logging.basicConfig(level=logging.INFO,
format='%(levelname)s - %(message)s')
>>> client = make_client(os.getenv('CVAT_HOST'), credentials=(
os.getenv('CVAT_USER'), os.getenv('CVAT_PASS')))
Now let’s create a dataset object corresponding to our training set. To follow along, you will need to substitute the task ID in the first line with the ID of the Flowers-train task that was printed when you ran the upload-flowers.py script.
>>> TRAIN_TASK_ID = 77708
>>> from cvat_sdk.pytorch import *
>>> train_set = TaskVisionDataset(client, TRAIN_TASK_ID)
INFO - Fetching task 77708...
INFO - Task 77708 is not yet cached or the cache is corrupted
INFO - Downloading data metadata...
INFO - Downloaded data metadata
INFO - Downloading chunks...
INFO - Downloading chunk #0...
INFO - Downloading chunk #1...
INFO - Downloading chunk #2...
INFO - Downloading chunk #3...
INFO - Downloading chunk #4...
INFO - All chunks downloaded
INFO - Downloading annotations...
INFO - Downloaded annotations
As you can see from the log, the SDK has downloaded the data and annotations for our task from the server. All subsequent operations on train_set will not involve network access.
But what is train_set, anyway? Examining it will reveal that it is a PyTorch Dataset object. Therefore we can query the number of samples in it and index it to retrieve individual samples.
>>> import torch.utils.data
>>> isinstance(train_set, torch.utils.data.Dataset)
True
>>> len(train_set)
354
>>> train_set[0]
(
<PIL.JpegImagePlugin.JpegImageFile image mode=RGB size=320x263 at 0x7F4CFE7E52D0>,
Target(
annotations=FrameAnnotations(tags=[
{
'attributes': [],
'frame': 0,
'group': None,
'id': 426655,
'label_id': 431494,
'source': 'manual'
}
], shapes=[]),
label_id_to_index=mappingproxy({431492: 0, 431493: 1, 431494: 2, 431495: 3, 431496: 4})
)
)
The sample format is broadly compatible with that used by torchvision datasets. Each sample is a tuple of two elements:
- The first element is a PIL.Image object.
- The second element is a cvat_sdk.pytorch.Target object representing the annotations corresponding to the image, as well as some associated data.
- The annotations in the Target object are instances of LabeledImage and LabeledShape classes from the CVAT SDK, which are direct representations of CVAT’s own data structures. This means that any properties you can set on annotations in CVAT — such as attributes & group IDs — are available for use in your code.
- In this case, though, we don’t need all this flexibility. After all, the only information contained in the original dataset is a single class label for each image. To serve such simple scenarios, CVAT SDK provides a couple of transforms that reduce the target part of the sample to a simpler data structure. For this scenario (image classification with one tag per image), the transform is called ExtractSingleLabelIndex. Let’s recreate the dataset with this transform applied:
>>> train_set = TaskVisionDataset(client, TRAIN_TASK_ID,
target_transform=ExtractSingleLabelIndex())
INFO - Fetching task 77708...
INFO - Loaded data metadata from cache
INFO - Downloading chunks...
INFO - All chunks downloaded
INFO - Loaded annotations from cache
Note that the task data was not redownloaded again, as it had already been cached. The SDK only made one query to the CVAT server, in order to see if the task had changed.Here’s what the sample targets look like with the transform configured:
>>> for i in range(3): print(train_set[i])
...
(<PIL.JpegImagePlugin.JpegImageFile image mode=RGB size=320x263 at 0x7F4CFE7E5720>, tensor(2))
(<PIL.JpegImagePlugin.JpegImageFile image mode=RGB size=320x213 at 0x7F4CFE7E56C0>, tensor(0))
(<PIL.JpegImagePlugin.JpegImageFile image mode=RGB size=500x330 at 0x7F4CFE7E5720>, tensor(4))
Each target is now simply a 0-dimensional PyTorch tensor containing the label index. These indices are automatically assigned by the SDK. You can also use these indices without applying the transform; they are provided by the label_id_to_index field on the Target objects.
ExtractSingleLabelIndex requires each sample to have a single tag. If a sample fails this requirement, the transform will raise an exception when that sample is retrieved.
Our dataset is now almost ready to be used for model training, except that we’ll also need to transform the image, as PyTorch cannot directly accept a PIL image as input. torchvision supplies a variety of transforms to convert and postprocess images, which can be applied using the transform argument. For example:
>>> import torchvision.transforms as transforms
>>> train_set = TaskVisionDataset(client, TRAIN_TASK_ID,
transform=transforms.ToTensor(),
target_transform=ExtractSingleLabelIndex())
INFO - Fetching task 77708...
INFO - Loaded data metadata from cache
INFO - Downloading chunks...
INFO - All chunks downloaded
INFO - Loaded annotations from cache
>>> train_set[0]
(tensor([[[0.5294, 0.5412, 0.5569, ..., 0.6000, 0.6118, 0.5804],
[0.5255, 0.5373, 0.5529, ..., 0.6000, 0.6118, 0.5804],
[0.5216, 0.5333, 0.5529, ..., 0.6000, 0.6078, 0.5725],
[...snipped...]
[0.1020, 0.1020, 0.1020, ..., 0.4980, 0.4980, 0.4980]]]), tensor(2))
Full model training & evaluation example
Equipped with the functionality that we just covered, we can now plug a CVAT dataset into a PyTorch training/evaluation pipeline and have it work the same way it would with any other dataset implementation.
Programming an entire training pipeline in interactive mode is a bit cumbersome, so instead we published two example scripts that showcase using a CVAT dataset as part of a simple ML pipeline. You can get these scripts from our blog repository.
The first script trains a neural network (specifically ResNet-34, provided by torchvision) on our sample dataset (or any other dataset with a single tag per image). You run it by passing the training task ID as an argument:
$ python3 train-resnet.py 77708
2023-02-03 16:55:17,268 - INFO - Starting...
2023-02-03 16:55:18,623 - INFO - Created the client
2023-02-03 16:55:18,623 - INFO - Fetching task 77708...
2023-02-03 16:55:18,867 - INFO - Loaded data metadata from cache
2023-02-03 16:55:18,867 - INFO - Downloading chunks...
2023-02-03 16:55:18,869 - INFO - All chunks downloaded
2023-02-03 16:55:18,901 - INFO - Loaded annotations from cache
2023-02-03 16:55:19,103 - INFO - Created the training dataset
2023-02-03 16:55:19,104 - INFO - Created data loader
2023-02-03 16:55:20,407 - INFO - Started Training
2023-02-03 16:55:20,407 - INFO - Starting epoch #0...
2023-02-03 16:55:32,451 - INFO - Starting epoch #1...
2023-02-03 16:55:44,086 - INFO - Finished training
It saves the resulting weights in a file named weights.pth. The evaluation script will read these weights back and evaluate the network on a validation subset—which you, again, specify via a CVAT task ID:
$ # this script uses the torchmetrics library to calculate accuracy
$ pip install torchmetrics
$ python3 eval-resnet.py 77709
2023-02-03 16:58:32,745 - INFO - Starting...
2023-02-03 16:58:33,669 - INFO - Created the client
2023-02-03 16:58:33,669 - INFO - Fetching task 77709...
2023-02-03 16:58:33,887 - INFO - Task 77709 is not yet cached or the cache is corrupted
2023-02-03 16:58:33,889 - INFO - Downloading data metadata...
2023-02-03 16:58:34,107 - INFO - Downloaded data metadata
2023-02-03 16:58:34,108 - INFO - Downloading chunks...
2023-02-03 16:58:34,109 - INFO - Downloading chunk #0...
2023-02-03 16:58:34,873 - INFO - All chunks downloaded
2023-02-03 16:58:34,873 - INFO - Downloading annotations...
2023-02-03 16:58:35,166 - INFO - Downloaded annotations
2023-02-03 16:58:35,362 - INFO - Created the testing dataset
2023-02-03 16:58:35,362 - INFO - Created data loader
2023-02-03 16:58:35,749 - INFO - Started evaluation
2023-02-03 16:58:36,355 - INFO - Finished evaluation
Accuracy of the network: 80.00%
Since training involves randomness, you may end up seeing a slightly different accuracy number.
Working with objects
Note: the code snippets from this section are also available as a Jupyter Notebook.
The PyTorch adapter also contains a transform designed to simplify working with object detection datasets. First, let’s see how raw CVAT shapes are represented in the CVAT SDK.
Open the Flowers-train task, click on the “Job #XXX” link, open frame #2, and draw rectangles around some sunflowers:
.png)
Press “Save”. Now, restart Python and reinitialize the client:
>>> import logging, os
>>> from cvat_sdk import *
>>> from cvat_sdk.pytorch import *
>>> logging.basicConfig(level=logging.INFO,
format='%(levelname)s - %(message)s')
>>> client = make_client(os.getenv('CVAT_HOST'), credentials=(
os.getenv('CVAT_USER'), os.getenv('CVAT_PASS')))
>>> TRAIN_TASK_ID = 77708
Create the dataset again:
>>> train_set = TaskVisionDataset(client, TRAIN_TASK_ID)
INFO - Fetching task 77708...
INFO - Task has been updated on the server since it was cached; purging the cache
INFO - Downloading data metadata...
INFO - Downloaded data metadata
INFO - Downloading chunks...
INFO - Downloading chunk #0...
[...snipped...]
INFO - All chunks downloaded
INFO - Downloading annotations...
INFO - Downloaded annotations
Note that since we have changed the task on the server, the SDK has redownloaded it.
Now let’s examine the frame that we modified:
>>> train_set[2]
(
<PIL.JpegImagePlugin.JpegImageFile image mode=RGB size=500x330 at 0x7F98AD088220>,
Target(
annotations=FrameAnnotations(
tags=[
{
'attributes': [],
'frame': 2,
'group': None,
'id': 426657,
'label_id': 431496,
'source': 'manual'
}
],
shapes=[
{
'attributes': [],
'elements': [],
'frame': 2,
'group': 0,
'id': 41000665,
'label_id': 431496,
'occluded': False,
'outside': False,
'points': [
170.1162758827213,
158.9655911445625,
349.43134126663244,
329.23956079483105
],
'rotation': 0.0,
'source': 'manual',
'type': 'rectangle',
'z_order': 0
},
[...snipped...]
]
),
label_id_to_index=mappingproxy({431492: 0, 431493: 1, 431494: 2, 431495: 3, 431496: 4})
)
)
You can see the newly-added rectangles listed in the shapes field. As before, the values representing the rectangles contain all the properties that are settable via CVAT.
Still, if you’d prefer to work with a simpler representation, there’s a transform for you: ExtractBoundingBoxes.
>>> train_set = TaskVisionDataset(client, TRAIN_TASK_ID,
target_transform=ExtractBoundingBoxes(
include_shape_types=['rectangle']))
INFO - Fetching task 77708...
INFO - Loaded data metadata from cache
INFO - Downloading chunks...
INFO - All chunks downloaded
INFO - Loaded annotations from cache
>>> train_set[2]
(
<PIL.JpegImagePlugin.JpegImageFile image mode=RGB size=500x330 at 0x7F98C414B7F0>,
{
'boxes': tensor([
[170.1163, 158.9656, 349.4313, 329.2396],
[255.2533, 59.5135, 458.6779, 256.9108],
[117.3765, 115.2670, 240.9382, 253.8971]
]),
'labels': tensor([4, 4, 4])
}
)
The output of this transform is a dictionary with keys named “boxes” and “labels”, and tensor values. The same format is accepted by torchvision’s object detection models in training mode, as well as the mAP metric in torchmetrics. So if you want to use those components with CVAT, you can do so without additional conversion.
Closing remarks
The PyTorch adapter is still new, so it has some limitations. Most notably, it does not support track annotations and video-based datasets. Still, we hope that even in its early stages it can be useful to you.
Meanwhile, we are working on extending the functionality of the adapter. The development version of CVAT SDK already features the following additions:
- A ProjectVisionDataset class that lets you combine multiple tasks in a CVAT project into a single dataset.
- Ability to control the cache location.
- Ability to disable network usage (provided that the dataset has already been cached).
If you have suggestions for how the adapter may be improved, you’re welcome to create a feature request on CVAT's issue tracker.





.svg)
.png)

.png)









.png)