



TL;DR: The quality of Deep Learning-based algorithms strongly depends on the quality of training data employed. This is especially true in the Computer Vision domain. Poor data quality leads to worse predictions, increased training times, and the need for bigger datasets. FiftyOne and CVAT can be used together to help you produce high-quality training data for your models. Keep reading to see how!

Introduction
Recently, the “Data-Centric movement” has been gaining popularity in the machine learning space. Over the last decade, improvements in machine learning primarily focused on models, while datasets remained largely fixed. As a community, we looked for better network architectures, created scalable models, and even implemented automatic architecture search. At present, however, the performance of our increasingly powerful models is limited by the datasets on which they are trained and validated.
In practice, datasets rarely stay fixed. They are constantly changing as more data is collected, annotated, and models are retrained. This iterative model improvement process is called Data Loop, illustrated in the image below.
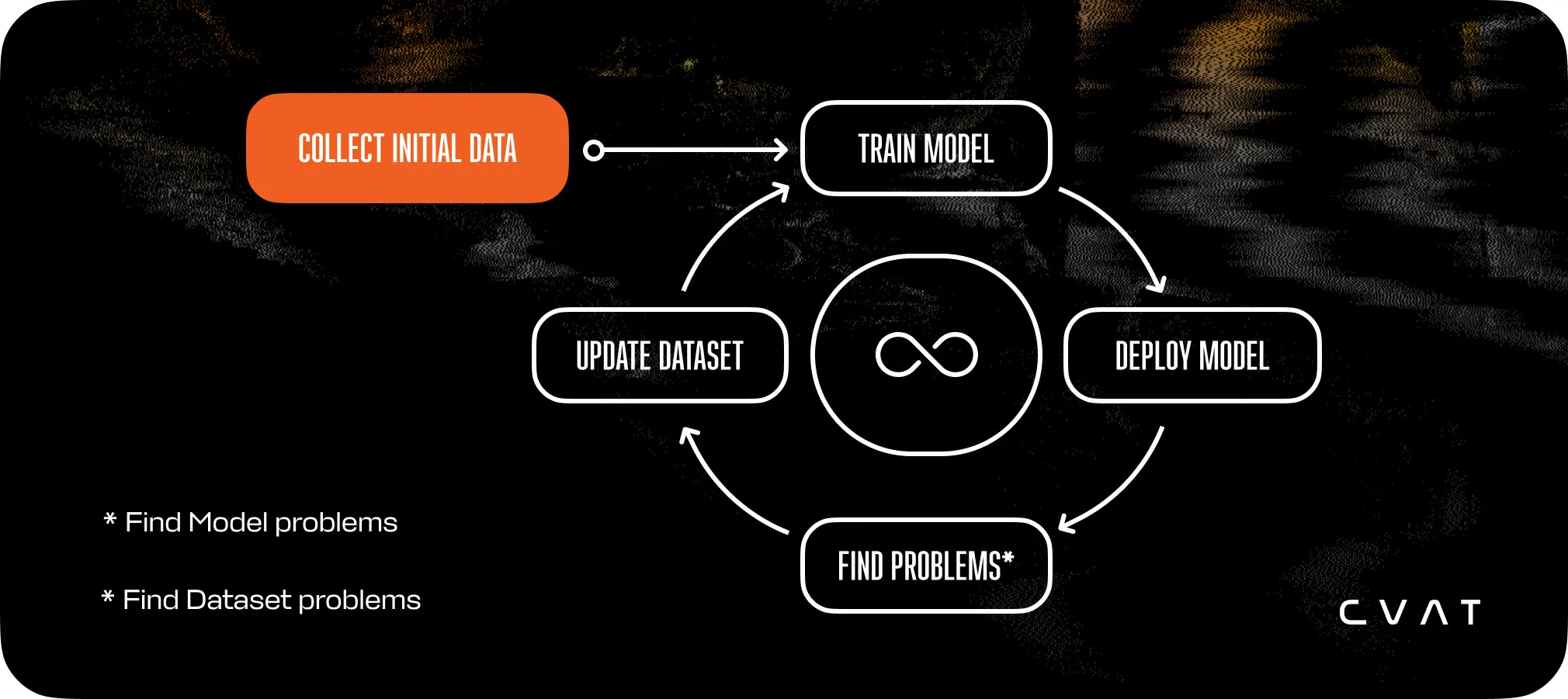
It is generally established that the more high-quality data you feed into the model, the better performance it achieves. The estimations are (eg. [1], [2]) that to reduce the training error by half, you need four times more data. But there’s a tradeoff: the more data you use in the training, the more time is needed for the training itself, as well for the annotation. And, unlike model training, because the annotation process is largely human-led, it can’t be simply sped up by more performant hardware.
That’s why it is important to keep datasets just the right size to be able to annotate data quickly and with high quality. The smaller the dataset, the better the annotation quality required to achieve good training results. Annotations must not contradict each other and be accurate. Since the annotations are done by people, they require validation. And that’s where tools, like FiftyOne and CVAT, can greatly help.
FiftyOne is an open-source machine learning toolset that enables data science teams to improve the performance of their computer vision models by helping them curate high quality datasets, evaluate models, find mistakes, visualize embeddings, and get to production faster.
CVAT is one of the leading open-source solutions for annotating Computer Vision datasets. It allows you to create quality annotations for images, videos and 3D point clouds and prepare ready-to-use datasets. It has an online platform and can be deployed on your computer or cluster. It is a scalable solution both for personal use and for big teams.
In this blog post we will demonstrate how you can use these tools to create high-quality annotations for a dataset, validate the annotations, and detect and fix problems.
Follow along with the code in this post through this Colab notebook.
Dataset Curation
To demonstrate a data-centric ML workflow, we will create an object detection dataset from raw image data. We will use images from the MS COCO dataset. This dataset is available in the FiftyOne Dataset Zoo. You can easily download custom subsets of the dataset and load them into FiftyOne. This dataset does have object-level annotations, but we will avoid using them in order to show how to annotate a dataset from scratch.
import fiftyone as fo
import fiftyone.zoo as foz
dataset = foz.load_zoo_dataset(
"coco-2017", split="validation", label_types=[],
)
# Visualize the dataset in FiftyOne
session = fo.launch_app(dataset)
While it is easy to load a large dataset into FiftyOne for visualization, it is much harder (and often a waste of time and money) to annotate an entire dataset. A better approach is to find a subset of data that would be valuable to annotate and start with that, adding samples as needed. A subset of a dataset can be useful if it contains an even distribution of visually unique samples, maximizing the informational content per image. For example, if you are training a dog detector, it would be better to use images from a range of different dog breeds rather than only using images of a single breed.
With FiftyOne, we can use the FiftyOne Brain to find a subset of the unlabeled dataset with visually unique images.
import fiftyone.brain as fob
# Generate embeddings
model = foz.load_zoo_model("clip-vit-base32-torch")
embeddings = dataset.compute_embeddings(model)
results = fob.compute_similarity(
dataset, embeddings=embeddings, brain_key="image_sim"
)
results.find_unique(500)
unique_subset = dataset.select(results.unique_ids)
session.view = unique_subset
Then we visualize these unique samples in the FiftyOne App.

Note: You can use the FiftyOne Brain compute_visualization() method to visualize an interactive plot of your embeddings to identify other patterns in your dataset.
These visually unique images give us a diverse subset of samples for training, while at the same time reducing the amount of annotation that needs to be performed. As a result, this procedure can significantly lower annotation costs. Of course, there is a lower bound to the number of samples needed to sufficiently train your model, so you will want to iteratively add more unique samples to your dataset as needed.
Dataset Annotation
Now that we’ve decided on the subset of samples in the dataset that we want to annotate, it’s time to add some labels. We will be using CVAT, one of the leading open-source annotation tools, to create annotations on these samples. CVAT and FiftyOne have a tight integration, allowing us to take the subset of unique samples in FiftyOne and load them into CVAT in just one Python command.
results = unique_view.annotate(
"annotation_key",
label_type="detections",
label_field="ground_truth",
classes=["airplane", "apple", …],
backend="cvat",
launch_editor=True,
)
Since this annotation process can take some time, we will want to make sure that our dataset is persisted in FiftyOne so that we can load it again at some point in the future when the annotation process is complete.
dataset.persistent = True
# Optionally give it a custom name
dataset.name = "cvat-fiftyone-demo"
# In the future in a new Python process
dataset = fo.load_dataset("cvat-fiftyone-demo")
After our data is uploaded into CVAT, a web browser page should be opened. We will see the main annotation window, where we can create, modify, and delete annotations. There are different tools available on this window toolbar, so we can draw polygons, rectangles, masks, and several other figures. In the object detection task, the primary annotation type is the bounding box. Let’s draw one using the corresponding tool from the toolbar.

Now, we can set the label and other attributes for the created rectangle. In this case, we used the “cat” label. After we’ve finished annotating this object, we can continue annotating other objects and images the same way. After all objects are annotated, we save work by clicking the Save button. Then, we can click the Menu button above and the Open the task button in the menu to open the task overview page.
In CVAT, the data is organized into Projects, Tasks, and Jobs. Each Project represents a dataset with multiple subsets (or splits) and can have one or many Tasks. You can manage tasks inside a project, join them into subsets, and export and import the data. A Task represents an annotation assignment for a person or several people. The Task can be treated as a dataset, but its primary role is to organize and split the big workload into smaller chunks. Each Task is divided into Jobs to be annotated.
CVAT supports different scenarios. In typical scenarios the datasets are big - from hundreds to millions of images. Datasets like these are annotated in teams divided into squads with different assignments: annotating, and reviewing of the annotated data. In CVAT, we can do both these assignments. We can assign people to jobs using the Assignee field. If there is a person to review our work and we want the annotations to be reviewed, we need to change the job Stage to “validation”:

Now, the reviewer can open the job and comment on the problems found. The user interface now will allow us to create Issues. The issues are just comments in the free form, though CVAT provides several options to mark common problems with annotation with just a single click.

Once the review is finished, we click the Save button, and return back to the task page. If everything is annotated correctly, we can mark the job as accepted and move onto other tasks. If there are problems found during the review, we can switch the job back to the annotation stage and assign it back to the annotator again.


Now, the annotator will be able to fix the problems and leave comments on the issues. This process can take several turns before the dataset is annotated correctly.
When we finish annotating this batch of samples we can again use the CVAT and FiftyOne integration to easily load the updated annotations back into FiftyOne.
unique_view.load_annotations("annotation_key")
Dataset Improvement
With the annotations loaded into our FiftyOne dataset, we can make use of the powerful querying and evaluation capabilities that FiftyOne provides. You can use them in the FiftyOne Python SDK and the FiftyOne App to analyze the quality of the annotations and the dataset as a whole. Dataset quality is a fairly vague concept that can depend on several factors, such as the accuracy of labels, spatial tightness of bounding boxes, class hierarchy in the annotation schema, “difficulty” of samples, inclusion of edge cases, and more. However, with FiftyOne, you can easily analyze any number of different measures of “dataset quality”.
For example, in object detection datasets, having the same object annotated multiple times with duplicate bounding boxes is detrimental to model performance. We can use FiftyOne to automatically find potential duplicate bounding boxes based on the IoU overlap between them, and then visually analyze if it actually is a duplicate or if it is just two closely overlapping objects.
import fiftyone.utils.iou as foui
from fiftyone import ViewField as F
foui.compute_max_ious(
dataset,
"ground_truth",
iou_attr="max_iou",
classwise=True,
)
dups_view = dataset.filter_labels(
"ground_truth", F("max_iou") > 0.75
)
session.view = dups_view
We can then tag these samples in the FiftyOne App as needing reannotation in CVAT.

Note: Other workflows FiftyOne provides to assess your dataset quality include methods to evaluate the performance of you model, ways to analyze embeddings, a measure of the likelihood of annotation mistakes, and more.
Using the FiftyOne and CVAT integration, we can send only the tagged samples over to CVAT and reannotate them.
reannotate_view = dataset.match_tags("needs_reannotation")
results = reannotate_view.annotate(
"reannotation",
label_field="ground_truth",
backend="cvat",
)

We can then load these annotations back into FiftyOne from CVAT with more confidence in the quality of our dataset. We can also export the created dataset into any of the common formats, including MS COCO, PASCAL VOC, and ImageNet, to be used in a model training framework directly from CVAT:

Next Steps
Now that we have an annotated dataset of sufficiently high quality, the next step is to start training a model. There are many ways you can train models by integrating FiftyOne datasets into your existing model training workflows or using CVAT to create a dataset ready for use.
However, the process doesn’t stop after the model is trained. This is just the beginning. As you evaluate your model performance, you will find failure modes of the model that can indicate a need for further annotation improvements or for additional data to add to your datasets to cover a wider range of scenarios.
This process of dataset curation, annotation, training, and dataset improvement is the heart of data-centric AI and is a continuous cycle that will lead to improved model performance. Additionally, this process is necessary for any production models to prevent them from becoming out of date as the data distribution shifts over time
Summary
In the current age of AI, and especially in the computer vision domain, data is king. Following a data-centric mindset and focusing on improving the quality of datasets is the most surefire way to improve the performance of your models. To that end, there are several open-source tools that have been built with data-centric AI in mind. FiftyOne and CVAT are two leading open-source tools in this space. On top of that, they are tightly integrated, allowing you to explore, visualize, and understand your datasets and their shortcomings, as well as to take action and efficiently annotate and improve your labels to start building better models.





.svg)
.png)

.png)









.png)