



The success of every modern computer vision system relies on one thing: data. Specifically, it relies on computer vision datasets that are well-annotated, diverse, and representative of the real world. These datasets are the fuel that drives object detection, semantic segmentation, visual recognition, and other tasks in AI.
But in 2026, computer vision is entering a new stage. The rise of generative adversarial networks, synthetic data pipelines, and 3D object detection has changed how teams think about data altogether. Systems are no longer trained on simple labeled images, they now rely on dynamic, multimodal datasets that capture texture, movement, and depth.
That's why choosing the right dataset has become less about quantity and more about context, structure, and how well it mirrors the world your model is meant to understand.
In this guide, we’ll break down the most influential and widely used computer vision datasets in 2026. Our goal is to compare them based on format, task coverage, relevance, and how well they support emerging use cases like autonomous driving, image captioning, scene recognition, and multimodal AI so that you can make an informed decision.
Criteria for Choosing a Computer Vision Dataset
Choosing the right computer vision dataset isn’t just about finding the largest collection of images. It’s about aligning the dataset with your task, architecture, and domain constraints.
In our opinion, there are four core factors that determine how useful a dataset will be. Let’s walk through each one so you can make confident, well-informed decisions.
Scale and Structure
Large datasets are essential for training deep learning models, but volume alone isn’t enough. A high-quality dataset should include:
- Well-balanced class distribution
- Clearly defined training, validation, and test sets
- Detailed annotations like bounding boxes, image-level labels, or segmentation masks
Datasets like COCO and Open Images V7 offer strong structure and multi-label annotations, making them effective for object detection and visual recognition tasks.
Diversity and Realism
Diversity improves generalization, and a model trained on narrow or biased data won’t perform well in production. That’s why we suggest you look for datasets with:
- Variation in environments, weather, lighting, and angles
- Representation across different demographics, geographies, and object types
- Realistic examples that match your deployment setting
For example, Cityscapes is known for capturing a wide range of urban driving scenarios, making it ideal for autonomous vehicles and pedestrian detection.
Use Case Fit
The dataset must support your specific application. A project focused on face verification requires different annotations than one focused on optical flow or handwriting recognition.
Before committing to a dataset, check:
- Are the right annotations included? (e.g., segmentation masks, temporal data, point clouds)
- Does the format align with your tooling? (COCO JSON, Pascal VOC XML, TensorFlow TFRecords, etc.)
- Is the level of detail sufficient for your model type?
The more aligned the dataset is with your use case, the less time you’ll spend converting formats or creating custom labels.
Adoption and Ecosystem
A well-adopted dataset benefits from mature documentation, tooling support, and community contributions. When a dataset is widely used, it’s easier to integrate with frameworks like YOLO.
Highly adopted datasets often come with:
- Active GitHub communities
- Prebuilt loaders and evaluation scripts
- Long-term maintenance and version tracking
High adoption also signals trust. If other teams are using the dataset for training ML models or benchmarking Vision AI systems, it’s more likely to fit into your pipeline without friction.
Computer Vision Datasets Compared
Every dataset plays a different role in how teams build, test, and refine machine learning models. Some focus on broad image classification, while others capture depth, motion, or real-world context for 3D object detection and scene understanding.
The table below gives a quick overview of each dataset’s strengths and best uses.
ImageNet
ImageNet is the cornerstone of modern computer vision. Introduced in 2009 by researchers at Princeton and Stanford, it provided the foundation for nearly every major breakthrough in deep learning and visual recognition over the last decade. Containing over 14 million labeled images across more than 21,000 categories, it became the standard benchmark for training and evaluating image classification models.
Data Format
Each image in ImageNet is annotated with an image-level label corresponding to a WordNet hierarchy concept. The dataset also includes bounding boxes for over one million images, allowing it to support object detection and localization tasks. The files are typically organized by category folders, making them easily exportable for formats like COCO JSON, TensorFlow TFRecords, or Pascal VOC XML.
Key Features
- Large-scale dataset covering diverse object categories
- Hierarchical labeling system aligned with WordNet
- Availability of both classification and detection subsets
- Supported by nearly all modern frameworks (PyTorch, TensorFlow, MXNet)
- Used as a pretraining source for transfer learning in downstream tasks
Best Use Cases
- Pretraining for deep learning models in classification and object recognition
- Transfer learning for custom datasets and domain adaptation
- Benchmarking model performance against established standards
- Fine-tuning tasks like scene recognition, face verification, or image captioning
Pros
- Extremely large and diverse dataset
- Universally supported across frameworks
- Strong benchmark for visual recognition models
- Enables faster convergence during model training
Cons
- Lacks domain-specific or multimodal annotations
- Some images are outdated or low-resolution
- Limited segmentation or 3D data support
- Licensing restrictions for certain research uses
Current Relevance
While newer datasets have emerged, ImageNet continues to hold immense value. Its influence is evident in how most Vision AI and generative model pipelines still begin with ImageNet pretraining. Even synthetic datasets are often validated against ImageNet accuracy benchmarks.
ImageNet also continues to be cited in thousands of academic papers annually and has appeared in over 40,000 research papers and 250 patents, reflecting its ongoing importance across academia and industry.
Even as models evolve toward multimodal and generative architectures, it continues to serve as the baseline reference for training, validation, and performance benchmarking in the field.
COCO (Common Objects in Context)
The COCO dataset, or Common Objects in Context, is one of the most widely used computer vision datasets for object detection, instance segmentation, and keypoint tracking.
Released by Microsoft in 2014, it set a new benchmark for real-world image understanding by emphasizing the importance of context. Rather than focusing on isolated objects, COCO captures how multiple objects interact within complex scenes, making it far more representative of real-world environments.
Data Format
COCO contains over 330,000 images, with more than 1.5 million object instances labeled across 80 core categories. Each image is annotated using COCO JSON format, which supports detailed metadata including segmentation masks, keypoints, and bounding boxes. It also includes captions and labels for image captioning and visual relationship tasks, expanding its utility beyond detection.
Key Features
- Rich annotations for object detection, keypoint estimation, and segmentation
- Context-driven images showing multiple overlapping objects
- Built-in captions for image captioning and visual recognition tasks
- Fine-grained instance segmentation masks
Best Use Cases
- Object detection and instance segmentation
- Image captioning and visual question answering
- Keypoint estimation and human pose detection
- Scene recognition and relationship modeling
- Benchmarking performance for Vision AI and autonomous driving models
Pros
- High-quality, richly annotated dataset
- Comprehensive support for multiple vision tasks
- Strong compatibility with open-source pipelines and frameworks
- Remains a universal benchmark across research and industry
Cons
- Limited category set compared to datasets like LVIS or Open Images
- Focuses primarily on everyday objects, lacking domain-specific scenes
- Computationally demanding for model training due to annotation density
Current Relevance
As of 2025, COCO remains one of the most cited and actively used computer vision datasets worldwide, appearing in over 60,000 academic papers in a single year. Its structured format, visual diversity, and consistent annotation standards make it an indispensable resource for anyone developing deep learning models in vision-related tasks.
From YOLO and Faster R-CNN to newer architectures like SAM and Ultralytics YOLO11, nearly every major object detection and segmentation benchmark is measured on COCO.
Open Images Dataset (by Google)
The Open Images Dataset, developed by Google, is one of the largest and most comprehensive computer vision datasets available today. First released in 2016 and continually expanded through multiple versions, it was designed to bridge the gap between image-level classification and fine-grained object detection, segmentation, and visual relationship understanding.
Its goal was to create a dataset that could support every stage of modern computer vision development from pretraining and model validation to object recognition and scene analysis.
Data Format
The dataset contains over 9 million images, each annotated with image-level labels and, for a subset, bounding boxes and segmentation masks. It supports a wide range of file formats, including COCO JSON and TensorFlow TFRecords, making it compatible with most ML frameworks. The Open Images V7 release added detailed object relationships, human pose annotations, and localized narratives for image captioning.
Key Features
- Over 600 object categories with bounding boxes for 15 million objects
- 2.8 million instance segmentation masks
- Image-level labels for over 19,000 visual concepts
- Annotations for object relationships and human poses
- Publicly hosted through Google Cloud for large-scale access
Best Use Cases
- Large-scale model training for image classification and object detection
- Instance segmentation and visual relationship modeling
- Benchmarking Vision AI or multimodal model performance
- Data augmentation and transfer learning across multiple visual domains
Pros
- Massive dataset with rich, multi-level annotations
- Covers a wide range of visual categories and contexts
- Excellent interoperability with standard formats and frameworks
- Supported by cloud-hosted infrastructure and community tools
Cons
- High storage and computational requirements
- Annotation inconsistencies in certain object categories
- Less suitable for domain-specific or specialized use cases
- Some subsets require Google authentication for access
Current Relevance
Open Images continues to play a crucial role for teams developing large-scale AI and Vision AI pipelines. Its scale and variety make it ideal for training deep learning models that require high visual diversity and balanced label distribution. Because it integrates both instance segmentation and image-level labeling, it remains useful for general-purpose computer vision tasks and multimodal pretraining.
As of 2025, it has appeared in over three thousands research papers and remains a reference point for deep learning and computer vision research across both academia and enterprise.
Pascal VOC
The Pascal Visual Object Classes (VOC) dataset is one of the earliest and most influential benchmarks in computer vision. Released between 2005 and 2012 as part of the PASCAL Visual Object Challenge, it helped standardize how researchers evaluate tasks like object detection, classification, and segmentation. Although smaller in scale compared to modern datasets like COCO or Open Images, Pascal VOC remains a cornerstone for model benchmarking and algorithm development.
Data Format
Pascal VOC includes roughly 20 object categories across thousands of labeled images. Each file comes with annotations in the Pascal VOC XML format, which defines bounding boxes, segmentation masks, and image-level labels. It’s widely supported by frameworks such as TensorFlow, PyTorch, and Keras, and it remains a go-to dataset for educational and prototype-level projects due to its simplicity and accessibility.
Key Features
- 20 well-defined object classes for detection and segmentation
- Clear annotation standards in XML format
- Includes both image classification and pixel-level segmentation tasks
- Consistent train, validation, and test splits for fair benchmarking
- Lightweight dataset size for fast experimentation
Best Use Cases
- Training and benchmarking small to medium-sized models
- Educational and academic computer vision research
- Model prototyping and pretraining before large-scale deployment
- Object detection and semantic segmentation experiments
Pros
- Easy to download, interpret, and integrate
- Lightweight, making it ideal for rapid testing
- Compatible with a wide range of frameworks and export formats
- Historically important for evaluating visual recognition systems
Cons
- Limited scale and class diversity
- Lacks the contextual depth of modern datasets
- No support for complex relationships or 3D objects
- Outdated for large-scale model training and evaluation
Current Relevance
Despite its age, Pascal VOC remains one of the most recognized names in the field. Its influence extends to nearly every major dataset released since, and its simple, structured annotations continue to teach new generations of data scientists the fundamentals of computer vision dataset design.
It’s widely used in academic settings for introducing new architectures or validating lightweight models before scaling up to larger datasets like COCO. The Pascal VOC format also remains foundational, with many modern datasets, such as Cityscapes and Open Images that borrow its structure and export compatibility.
While it may no longer set state-of-the-art benchmarks, its influence persists in transfer learning, model validation, and open-source frameworks. Many real-world projects still use Pascal VOC as a quick and reliable dataset for initial model training or small-scale proof-of-concept experiments.
LVIS
The Large Vocabulary Instance Segmentation (LVIS) dataset was introduced to address a critical limitation in earlier benchmarks like COCO: the lack of diversity and long-tail representation. Developed by researchers from Facebook AI Research, LVIS builds on the COCO dataset but dramatically expands the number of object categories and annotations, making it ideal for fine-grained object detection and instance segmentation.
Data Format
LVIS includes over 1,000 object categories across approximately 160,000 images. Each image contains detailed instance segmentation masks, bounding boxes, and object-level annotations stored in JSON format. The dataset structure is COCO-compatible, allowing seamless use with the same APIs, frameworks, and annotation tools. It is also organized to capture both frequent and rare object classes, enabling balanced model training for long-tail distributions.
Key Features
- Over 1,200 object categories, from common to rare classes
- More than 2 million segmentation masks with precise boundaries
- Compatibility with COCO APIs and annotations
- Inclusion of long-tail and fine-grained object categories
- Designed to improve generalization in real-world visual recognition tasks
Best Use Cases
- Instance segmentation and object detection
- Long-tail recognition and fine-grained classification
- Transfer learning and domain adaptation research
- Benchmarking generalization and model robustness
Pros
- Large number of detailed object categories
- Excellent representation of rare and fine-grained classes
- Compatible with existing COCO tools and pipelines
- Ideal for testing generalization and open-vocabulary models
Cons
- More complex and computationally intensive than COCO
- Imbalanced category distribution can complicate training
- Limited support for non-visual or 3D data
- Annotation errors may appear in rare classes
Current Relevance
By 2026, LVIS will be one of the most important datasets for training deep learning models that need to handle a wide variety of object types. It’s widely used for research in instance segmentation, open-vocabulary detection, and fine-tuning models for edge cases in autonomous vehicles, robotics, and scene understanding.
LVIS’s structure also makes it particularly useful for transfer learning, as models trained on LVIS tend to perform better on datasets with rare or domain-specific objects. With the rise of open-vocabulary and multimodal AI systems, LVIS continues to be a standard dataset for evaluating how well models generalize beyond high-frequency object classes.
ADE20K
The ADE20K dataset, short for the ADE (Annotated Dataset) for Scene Parsing, is one of the most comprehensive resources for semantic segmentation and scene understanding. Developed by MIT’s Computer Science and Artificial Intelligence Laboratory (CSAIL), it focuses on parsing complex scenes with pixel-level precision. Unlike datasets centered on individual objects, ADE20K provides a holistic understanding of both foreground and background elements within an image.
Data Format
ADE20K contains over 25,000 images with detailed pixel-level annotations across 150 object and stuff categories. Every image is manually annotated to include all visible objects and regions, ensuring accurate scene segmentation. The dataset is distributed in a format compatible with COCO JSON and Pascal VOC XML, making it easy to integrate with popular frameworks for training deep learning models. It also includes pre-defined train, validation, and test splits for reproducibility and benchmarking.
Key Features
- Pixel-level semantic segmentation for 150 object categories
- Covers both “object” and “stuff” classes for complete scene parsing
- Manually annotated by trained professionals for precision
- Compatible with major frameworks like TensorFlow, PyTorch, and Detectron2
- Frequently used for training segmentation models such as DeepLab and PSPNet
Best Use Cases
- Semantic segmentation and scene parsing
- Training and evaluation of segmentation and panoptic models
- Benchmarking transformer-based architectures for visual understanding
- Validation for synthetic or domain-adapted datasets
Pros
- High-quality, dense annotations with strong accuracy
- Balanced coverage of object and environmental categories
- Maintained by a reputable academic research group
- Ideal for developing and benchmarking segmentation models
Cons
- Limited dataset size compared to Open Images or COCO
- Focuses mainly on segmentation, with no instance or 3D data
- Computationally heavy due to detailed pixel-level labeling
Current Relevance
As of 2025, ADE20K remains a top benchmark for semantic segmentation and scene recognition research.
Its fine-grained annotations make it essential for developing models that must interpret complex, multi-object environments, particularly in fields like robotics, autonomous driving, and aerial image segmentation.
Even as new datasets emerge, it continues to define what “high-quality segmentation data” looks like in the era of large-scale Vision AI and multimodal learning.
Examples of Use Cases for Computer Vision Datasets
Every team uses computer vision datasets differently. For some, it’s about training models that recognize products on a shelf. For others, it’s about helping a car see the road or a robot understand its surroundings.
So to shed a bit more light on how they’re used, let’s look at some of the most common and emerging applications shaping the future of computer vision today.
1. Image Classification and Object Recognition

This remains the entry point for most computer vision systems. Datasets like ImageNet, COCO, and Open Images have become industry benchmarks for training models to recognize objects, people, and scenes in real-world contexts.
These datasets are ideal for applications such as:
- Product recognition in retail and e-commerce
- Visual search and image tagging
- Quality inspection in manufacturing
- Face or gesture recognition in security systems
ImageNet provides broad visual diversity for general classification, while COCO adds contextual depth through overlapping objects and captions. LVIS and Pascal VOC are excellent choices for refining recognition models on more detailed or long-tail object categories.
2. Object Detection and Instance Segmentation

For models that need to locate and classify multiple objects in a single frame, COCO, LVIS, and Open Images remain the gold standard. These datasets feature dense annotations, segmentation masks, and bounding boxes that teach AI to interpret complex, multi-object environments.
Key applications include:
- Autonomous retail checkout and shelf monitoring
- Crowd and pedestrian detection
- Industrial defect and anomaly detection
- Wildlife tracking and environmental monitoring
LVIS extends COCO’s capabilities with over 1,000 categories, supporting fine-grained detection and rare-object recognition, while Open Images helps scale detection to millions of diverse scenes.
3. Scene Understanding and Semantic Segmentation
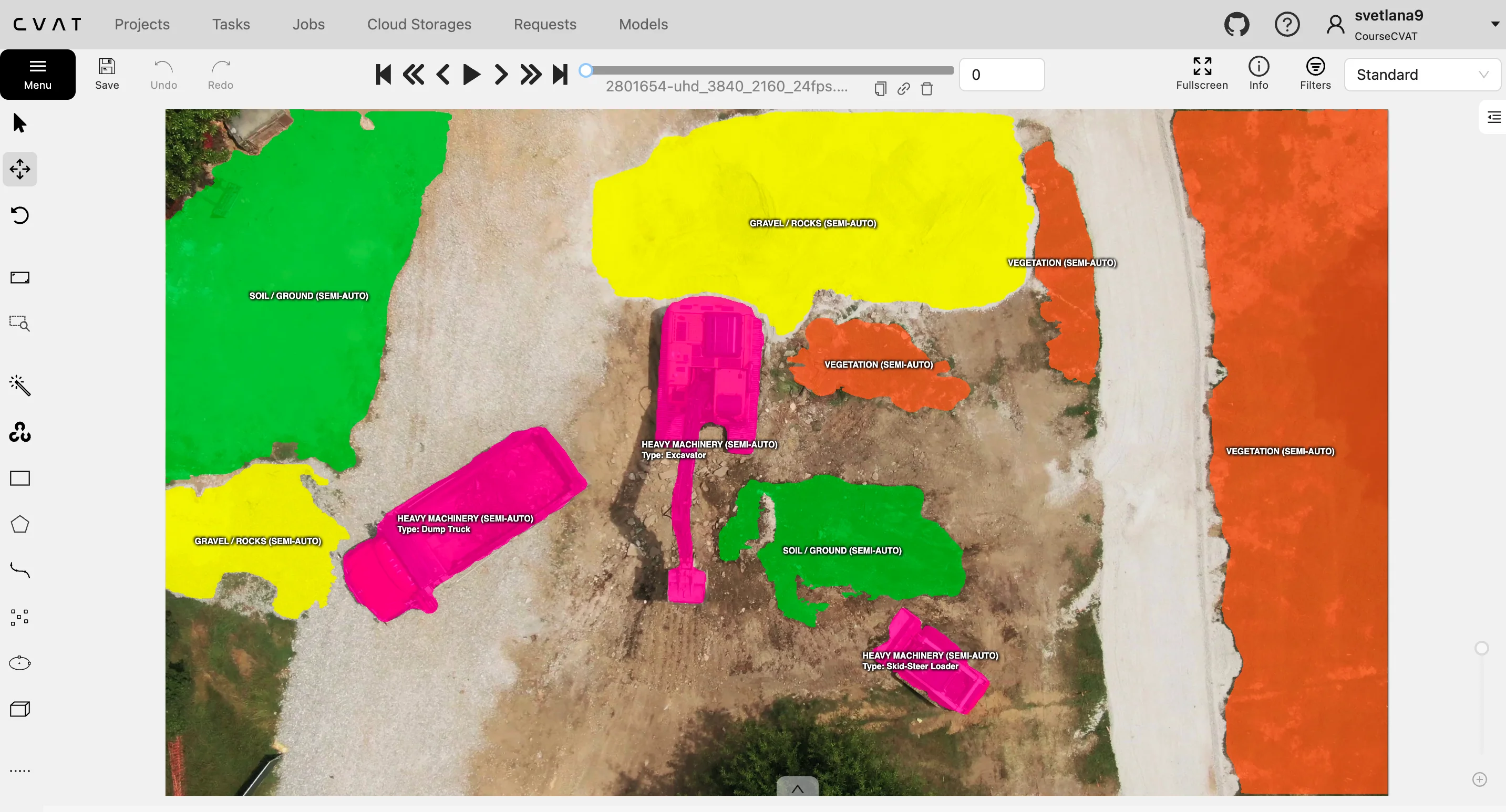
When the goal is to help AI understand the entire scene, datasets like ADE20K and Cityscapes are indispensable. They include pixel-level labels for every region of an image, allowing models to learn spatial relationships and contextual awareness.
Use cases include:
- Smart city infrastructure and traffic analytics
- AR/VR environment mapping
- Interior design and robotics navigation
- Aerial and satellite imagery analysis
ADE20K covers both “stuff” (background) and “object” classes for scene parsing, while Cityscapes provides high-resolution street-level data ideal for autonomous vehicles.
4. 3D Object Detection and Spatial Mapping
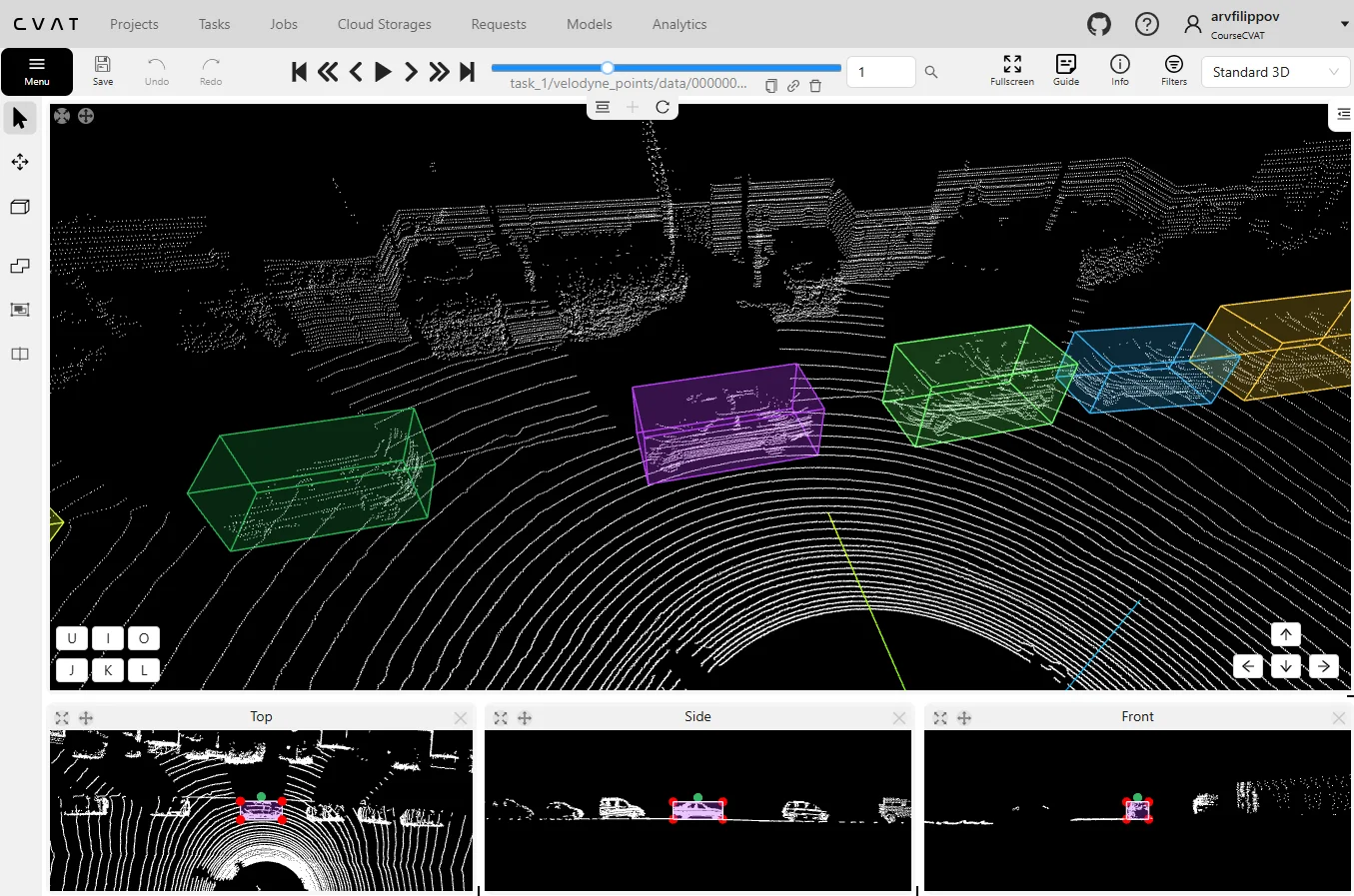
Datasets like KITTI, nuScenes, and Matterport3D power AI systems that must understand depth, motion, and geometry. These are critical for self-driving cars, drones, and robots operating in 3D space.
They support tasks such as:
- LiDAR and sensor fusion for autonomous driving
- Drone-based warehouse mapping
- Robotics path planning and obstacle detection
- Depth estimation and 3D reconstruction
KITTI and nuScenes combine LiDAR, radar, and camera data to train robust perception models, while Matterport3D provides high-quality 3D scans for indoor spatial analysis.
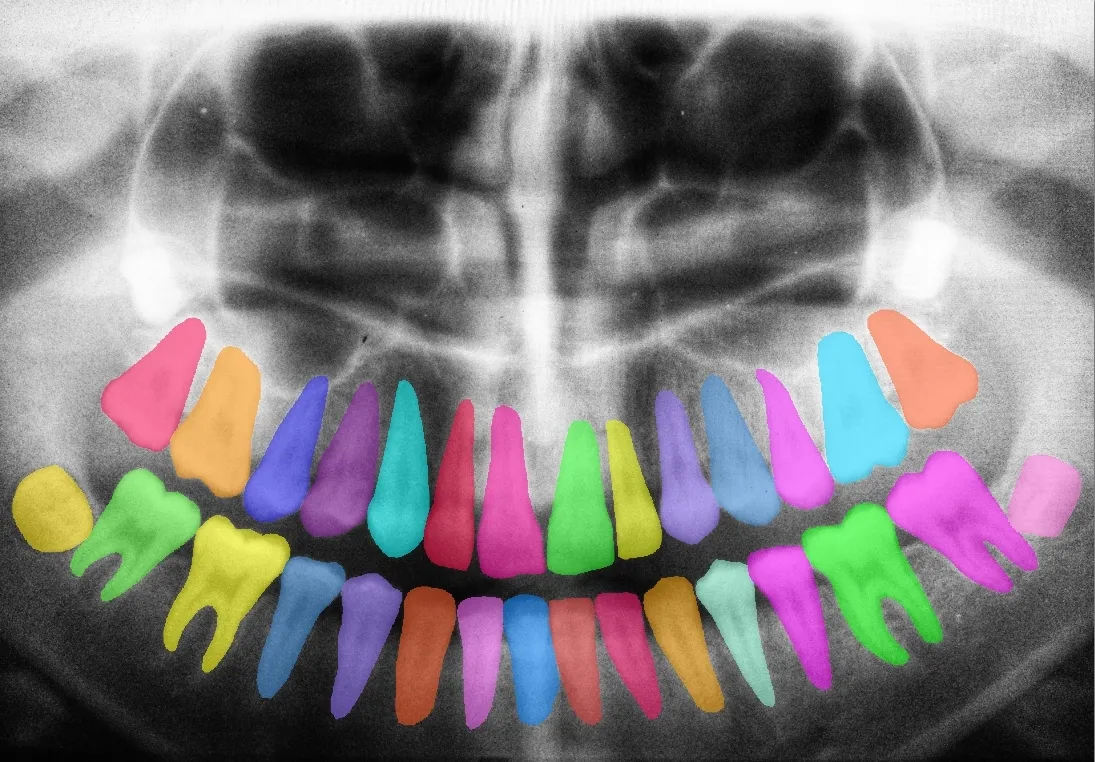
5. Medical Imaging and Healthcare AI

In medical data annotation, computer vision datasets help accelerate diagnosis and automate complex visual analysis. Datasets such as LIDC-IDRI, BraTS, and CheXpert provide expertly labeled scans across radiology and pathology disciplines.
Common applications include:
- Tumor segmentation and lesion detection
- 3D organ modeling and reconstruction
- Disease classification and triage systems
- Automated medical image review and workflow optimization
These datasets mirror the structure of segmentation datasets like ADE20K, but focus on medical-specific modalities such as CT and MRI.
What You Need to Know to Choose the Right Dataset for Your Project
Every great computer vision model starts with a decision: what data should it learn from? And that choice matters more than most people realize, as the dataset shapes how your model sees the world, what it pays attention to, and how well it performs once it faces the real thing.
If you’re building something practical, start with the classics. ImageNet and COCO are perfect for object recognition, pedestrian detection, or face recognition projects where variety and accuracy matter.
But as models grow more specialized, many teams are moving beyond general-purpose datasets to ones built for specific challenges, like Open Images V7 for large-scale training, KITTI for 3D object detection, or ADE20K for scene understanding.
And for projects where no ready-made dataset quite fits, the next step is to collect and label their own data. That’s where CVAT can really make a difference.
With CVAT, teams can turn raw data into structured, ready-to-train datasets tailored to their exact use case. You can upload images or videos, organize them into datasets, and apply consistent, high-quality annotations using tools like bounding boxes, polygons, segmentation masks, and keypoints. Once complete, datasets can be exported in formats compatible with TensorFlow, PyTorch, and other ML frameworks, making it easy to move from data preparation to model training without friction.
If you’re ready to start building, CVAT gives you everything you need to manage, label, and refine your datasets in one place.
- Use CVAT Online if you prefer a managed cloud solution with no setup required, offering access to advanced labeling and automation features.
- Set up CVAT Community if you want a self-hosted, open-source version that provides full control and customization.
- Or, choose CVAT Enterprise if your organization needs a secure, scalable, feature-rich, self-hosted solution with professional support and tailored integrations.




.svg)
.png)

.png)









.png)