


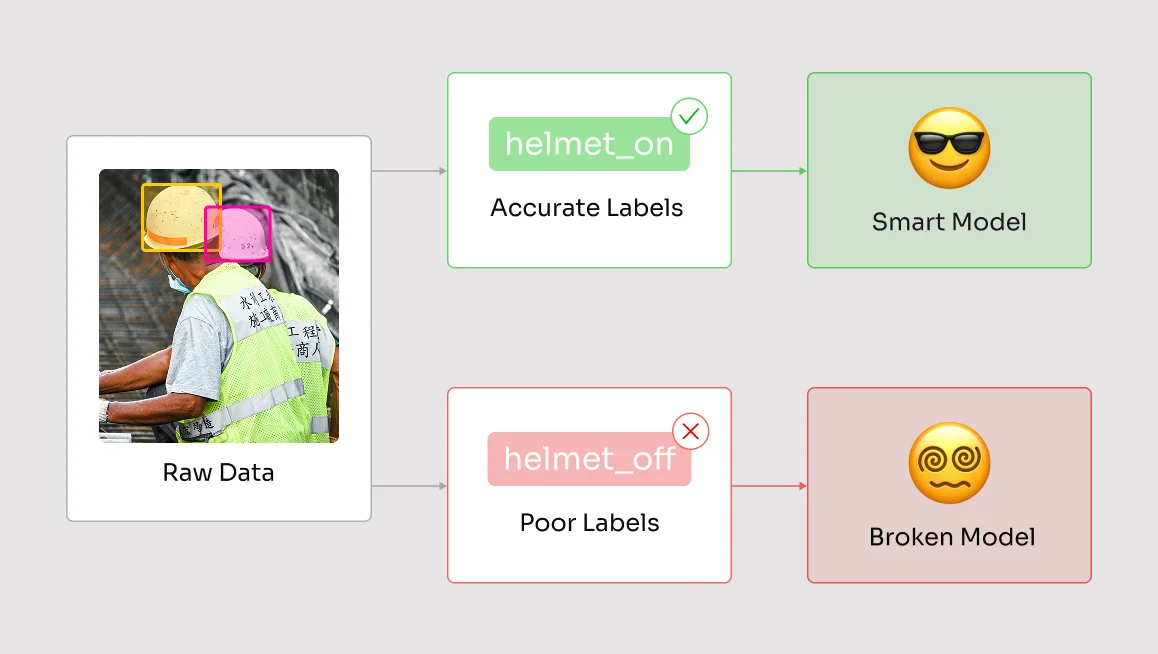
In the world of machine learning and neural networks, annotations are more than labels. They are the ground truth that shapes how models learn, adapt, and perform.
For example, in an autonomous driving system, correctly labeling trees and other road hazards helps the neural network distinguish between safe and unsafe obstacles, allowing it to make accurate, split-second decisions when navigating complex traffic scenarios.
At its core high-quality annotations guide the learning algorithm, reduce biases, and improve inference. And with the right annotation strategies and smart tools like CVAT to streamline and refine the process, teams can create training datasets that lead to better model performance.
Why High-Quality Data is Critical for Model Training
High-quality annotations are essential because they directly shape how a machine learning model understands its training data.

Without precise and consistent labels, even the most advanced architecture, whether it is a convolutional neural network for image recognition or an object detection model for computer vision, will misinterpret patterns. This leads to lower accuracy, poor inference, and unreliable results when the model is deployed.
Impact on Model Training
When annotations are precise, consistent, and aligned with the project’s objectives, the model can learn the correct patterns and relationships within the dataset. This results in stronger generalization, faster convergence, and higher performance in production.
However, when annotations are flawed, the model’s ability to interpret data is compromised. This is where the Garbage In, Garbage Out (GIGO) principle comes into play.
No matter how sophisticated the architecture or training algorithm, if the labeled data fed into the model is inaccurate or inconsistent, the output will be equally unreliable. Poor annotations can lead to overfitting, underfitting, or skewed model bias, all of which degrade predictive performance.
Key effects of annotation quality on model training include:
- The accuracy of learned patterns and feature recognition
- Model confidence scores during inference
- Overall training time and convergence speed
- Increasing or reducing the risk of overfitting to mislabeled data
- Enhancing or limiting the model’s ability to generalize to unseen scenarios
Ultimately, investing in high-quality annotations is the foundation for a model’s ability to deliver reliable, actionable insights. Without this, even large datasets and advanced algorithms will fail to produce dependable results. (e.g., models trained on the refined COCO‑ReM dataset converge faster and score higher than those using original COCO annotations)
Examples of Errors from Poor Annotation
In machine learning, even small annotation mistakes in the training dataset can have significant downstream effects on an ML model’s behavior.
During data preparation, these errors often remain hidden, only to surface during the inference stage when the machine learning algorithm must evaluate and predict in real-world conditions.
For instance, in medical classification tasks, an incorrectly annotated MRI scan, such as tagging a benign tumor as malignant, could trigger unnecessary treatment, impacting both the patient and the healthcare production system.
Other impacts of annotation errors include:
- Model confusion on edge cases – Neural network architectures misinterpret visually similar features or overlapping classes.
- Reduced confidence scores – The training model produces low model confidence scores during evaluation, weakening performance metrics.
- Propagation of bias – Systematic labeling errors introduce biases into the learning algorithm and affect correlation patterns.
- Misclassification in critical applications – Incorrect predictions in safety-critical domains such as predictive maintenance, financial fraud detection, or medical diagnostics.
- Poor generalization – The ML model fails to adapt to new datasets, validation sets, or unseen scenarios in production.
Addressing these risks requires rigorous validation systems, manual review of annotations, and re-trainings supported by quality-controlled data pipelines.
This can be done through platforms like CVAT, which have built-in audit trails and annotation consistency checks and which can be integrated with TensorFlow or PyTorch workflows to ensure the training set remains accurate, helping the learning algorithm reach optimal performance in both classification and regression tasks.
The Role of High-Quality Data in Neural Network Training
Neural networks are only as strong as the data that teaches them. In machine learning, annotations transform raw data into meaningful training signals, giving the learning algorithm the context it needs to recognize patterns, classify inputs, and make accurate predictions.
Annotation as a Source of Truth
In supervised learning, high-quality annotations serve as the ground truth that a machine learning algorithm depends on to learn from its training set. Whether the task involves image recognition, binary classification, or regression, accurate labels guide the training process, allowing the model to identify features, optimize hyperparameters, and improve predictive performance.
When your annotated data is accurate, the outputs are more reliable, the loss function converges faster, and performance metrics improve in both training and validation sets.
Key benefits of treating annotations as a source of truth include:
- Providing a reliable foundation for ML model training and re-trainings
- Reducing confusion in decision trees, random forest, and neural network architectures
- Improving generalization in deep learning models, from CNNs to large language models
- Supporting effective cross-validation for more robust predictions
- Enabling reproducible workflows for distributed training across GPUs and cloud platforms
By incorporating manual review, annotation guidelines, and consistent quality checks into the workflow, teams can ensure annotations remain accurate over time.
Bias and Noise Reduction
Even the most advanced deep learning architectures can fail if the training dataset is filled with bias or noise. Poorly annotated data skews the learning algorithm’s understanding of correlations, causing systematic errors that can harm both model accuracy and customer trust.
High-quality annotation reduces these risks by ensuring consistency across the training set and minimizing human error in the labeling process. Whether using supervised learning for classification or unsupervised learning methods like k-means clustering, accurate labels help the model predict with greater confidence and adapt to varied test data in production systems.
Here are some ways that precise annotations help reduce bias and noise:
- Maintaining consistent class definitions across the entire training dataset
- Eliminating mislabeling that introduces false correlations into the regression model or clustering algorithms
- Preventing performance degradation in models used for critical tasks like predictive maintenance or spam detection
- Improving gradient descent convergence by reducing variability in the training process
- Supporting re-trainings and model evaluation cycles that catch emerging biases early
By combining automated machine learning pipelines with manual review, federated data strategies, and scalable annotation tools, teams can deliver ground truth data that is free from systemic bias.
How High-Quality Annotation Workflows Are Built — and How CVAT Helps
High-quality annotation workflows don’t happen by accident. They are the result of structured processes, clear guidelines, and reliable tools. CVAT supports these workflows by providing a collaboration platform that enables accuracy, scalability, and quality control for every stage of the machine learning data labeling process.
Redundancy and Consensus for Reliability
Using multiple annotators per task helps achieve consensus on labels, reducing the likelihood of errors in the training dataset. CVAT allows for configurable redundancy so ML model training benefits from diverse perspectives while maintaining accuracy through agreement-based labeling.
The benefits of this include:
- Fewer mislabeled examples in the training set
- Stronger ground truth accuracy for supervised learning
- Reduced bias in machine learning model outputs
Annotation Consistency Over Time
Consistency ensures that features are labeled the same way across the training set. CVAT supports predefined label sets (such as object categories like car, pedestrian, traffic light) and annotation guidelines (which define how these labels should be applied, including attributes or tagging rules). These guidelines make it easier for distributed teams to maintain uniformity in supervised learning workflows.
Built-In Quality Control
CVAT provides several automated QA and control mechanisms that help catch annotation errors early and streamline the training process. These include:
- Ground Truth jobs: A curated validation set is used as a benchmark, allowing statistical evaluation of annotation quality across the dataset.
- Honeypots: Hidden validation frames are randomly inserted into jobs, helping monitor annotation accuracy in real time without alerting annotators.
- Immediate Job Feedback: Once a job is completed, CVAT automatically evaluates it against GT or honeypots and shows the annotator a quality score with the option to correct mistakes immediately.
Traceability and Audit Trails
Traceability is critical for large-scale datasets, which is why CVAT has an analytics page for all your project data, ensuring teams can track events, annotations and more. This transparency is essential for model evaluation, regulatory compliance, and maintaining customer trust.
Flexible Workflows for Diverse Data
From image recognition to 3D sensor data, CVAT adapts to different data types and annotation styles. Flexible task management, support for multiple annotation formats, and integration with ML pipelines make it suitable for varied AI and deep learning applications.
Best Practices for Ensuring High-Quality Data
The structured workflows above provide the foundation for producing reliable training data at scale. But building a strong annotation pipeline is only part of the equation. Maintaining quality over time requires discipline, clear standards, and continuous evaluation.
By following these proven best practices, teams can ensure that every dataset, whether used for image recognition or predictive modeling, remains accurate, consistent, and free from bias.
Follow Annotation Guidelines
Clear, documented annotation guidelines are essential for ensuring that every label in a training set is applied consistently, regardless of who is doing the work. Without them, inconsistencies can creep in, creating noise in the training data and reducing the accuracy of the machine learning model.
{{labeling-specs-banner="/blog-banners"}}
How to implement clear annotation guidelines:
- Define each label class with clear descriptions and examples.
- Specify rules for handling edge cases and overlapping classes.
- Document attributes that need to be captured (for example, color, orientation, or object state).
- Ensure guidelines are regularly updated and accessible to all annotators.
For a deeper breakdown of what makes strong labeling specifications, see CVAT’s guide on creating data labeling specifications.
Conduct Annotation Review Cycles
Even experienced annotators make mistakes, which is why conducting annotation review cycles is so critical. Review cycles help catch errors early, before flawed data is used in ML model training.
How to conduct annotation review cycles:
- Schedule periodic reviews of completed annotations.
- Use CVAT’s Immediate Job Feedback to automatically evaluate annotations against ground truth or honeypots and provide annotators with instant quality scores.
- Assign multiple reviewers for critical or complex datasets.
- Use feedback loops to train annotators on corrections.
CVAT’s built-in review mode allows reviewers to approve, reject, or edit annotations in real time. Task assignment tools ensure the right people review the right data, while commenting features make feedback easy to share.
Perform Continuous Model Evaluation
A dataset is never truly “finished.” Models improve when their training data is updated and re-evaluated. Continuous model evaluation measures whether annotation improvements are actually boosting accuracy, reducing loss, and improving performance metrics.
How to perform continuous model evaluation:
- Benchmark model performance before and after annotation updates.
- Track changes in accuracy, precision, and recall over time.
- Re-train models when new patterns or edge cases are identified.
CVAT makes model evaluation easy. We integrate with ML pipelines so teams can quickly export labeled datasets, test them in TensorFlow or PyTorch, and compare results. Plus, our version control ensures teams can roll back to previous annotations and measure improvement with confidence.
The Data-Driven Path to Smarter Annotations
Adopting best practices like clear guidelines, structured review cycles, and continuous model evaluation helps you build a feedback-driven workflow where data constantly informs better decisions.
CVAT makes this easier by giving organizations the tools to embed their standards into the workflow, collaborate effectively across teams, and integrate seamlessly with existing ML pipelines.
Because in a world where machine learning models are judged by their ability to perform in real-world scenarios, data labeling quality is non-negotiable. The more accurate your ground truth, the more reliable your predictions, and the faster your AI projects deliver real value.
Don’t let poor annotations hold your models back. Join the thousands of teams using CVAT to build better datasets, streamline labeling, reduce errors, and deliver higher-performing AI faster. Get started now.




.svg)
.png)

.png)









.png)