



As AI teams scale their machine learning operations, they face a critical decision:
“How do we build and maintain a thriving data annotation pipeline without deployment hassles?”
This choice becomes especially crucial as datasets grow, team sizes expand, and security requirements intensify. Some teams need the agility and ease of cloud solutions, while others require the control and security of on-premise deployments.
This isn't just an IT decision—it's a strategic choice impacting development speed, data security, team collaboration, and regulatory compliance. Get it right, and your annotation workflow becomes a competitive advantage. Get it wrong, and you could face costly delays, security vulnerabilities, or scaling limitations that hamper your AI development.
CVAT addresses this challenge by offering two platforms, CVAT Online and CVAT Enterprise, designed for different team setups and deployment requirements. This guide will help you understand their key differences and choose the right annotation platform for your use case.
Why Care About Data Annotation Infrastructure?
Imagine your ML team is ready to train the next model iteration, but...
- Half of your annotated dataset is trapped in incompatible formats,
- Your remote labeling team is using old guidelines,
- and nobody knows which annotations have been quality-checked.
Sounds familiar?
While AI discussions often center on model architecture and compute, poor annotation infrastructure can derail your initiatives as quickly as attempting to train ResNet on a CPU.
So, why should ML teams care about their annotation infrastructure?
One Data Breach Can Destroy Your Project
Data breaches and compliance violations in annotation workflows can derail AI projects and company reputations overnight. Scale AI's recent data exposure speaks for itself. Many teams discover similar security gaps too late, facing issues like:
- Sensitive training data exposed due to inadequate access controls during the labeling process.
- Undetected data leakage across storage systems as datasets transfer between annotation tools.
- Missing or incomplete audit trails that obstruct proper data governance.
- No systematic way to track data access creates compliance issues.
Bad Data Quality Ruins Your Models
Poor annotation infrastructure leads to low-quality annotated data, resulting in poor-performing models—a "garbage in, garbage out" (GIGO) trap that rookie ML teams fall into. The common issues include:
- No standardized way to distribute and update labeling guidelines across distributed teams.
- Errors accumulate for weeks before detection due to a lack of real-time quality monitoring.
- Missing tools for cross-checking annotations between team members lead to systematic bias.
- Inability to enforce consistent labeling schemas across projects and datasets.
If your main MLOps challenge is improving your labeled data quality, check our blog post How Data and Annotation Quality Improves ML Model Training for recommendations on building precise training datasets.
Infrastructure Bottlenecks Delay Launches
Manual data handling, inconsistent tooling, and rigid systems that can't scale with your labeling needs slow down model development. Teams frequently encounter obstacles with:
- Manual processes that fail beyond a few annotators
- No way to efficiently propagate labeling instruction changes across ongoing projects.
- Inability to distribute work across multiple annotation teams
- Limited options for automating repetitive labeling tasks that take up annotator time.
- Datasets stuck in incompatible formats cause ongoing conversion challenges.
Hidden Costs Blow Up Budgets
Finally, poor annotation infrastructure leads to ballooning costs that exceed initial budgets. Hidden expenses include:
- Teams struggle to coordinate work effectively, resulting in suboptimal resource allocation.
- Annotators spend more time struggling with clunky interfaces than labeling data.
- Growing technical debt and maintenance overhead from cobbled-together solutions.
- Teams are forced to re-annotate the same data repeatedly due to constant rework and quality issues.
How do teams avoid infrastructure traps while maintaining speed and quality in their AI projects?
The annotation landscape has evolved to address these challenges through two approaches: managed cloud platforms optimized for rapid deployment and ease of use, and self-hosted solutions built for control, scale, and security.
Understanding this divide is crucial for choosing the right path for your team's needs and constraints. Let's examine how CVAT's two platforms address these requirements.
CVAT Online: Cloud-First Annotation for Teams with High Throughput and Speed
CVAT Online is a cloud-hosted platform for annotating images, videos, and 3D point clouds. It is designed for computer vision teams to scale data labeling operations without managing infrastructure. It handles everything from basic object detection to complex instance segmentation, managing all computing resources, storage, and scaling automatically.
Its power for modern computer vision teams lies in transforming visual data annotation from a technical obstacle into a strategic advantage.
Small to medium-sized teams find that the platform’s mature infrastructure exceeds what they can maintain internally, particularly when scaling across multiple projects or distributed teams.
CVAT handles hosting, dataset storage, and platform upgrades, so teams with limited engineering resources don’t have to worry about data backups, uptime monitoring, or fixes rollout. As a result, teams report 30–40% faster iteration cycles and quicker model deployment.
CVAT Online Features
Thanks to its cloud-based setup, CVAT Online allows annotation teams and machine learning engineers to collaborate in real time across time zones and monitor progress and quality from a single workspace. They can keep dataset versions in sync globally and A/B test annotation approaches, all without provisioning infrastructure.
This setup isn’t right for every team. If you work in regulated fields like healthcare, biotech, government, defense, financial services, or automotive, or if you deal with sensitive research data or personal information, you may need to store your datasets in your own private cloud or on your own servers, sometimes completely isolated, with specific security measures like custom single sign-on, role-based access and audit logs.
For these cases, CVAT Enterprise delivers the same experience as CVAT Online, but in your VPC or on-prem, with complete security, governance, and integration control.
CVAT Enterprise: On-Premise Power and Control for Teams in Regulated Industries
CVAT Enterprise is a self-hosted platform for annotating images, videos, and 3D point clouds, designed for machine learning teams that need to keep data and workflows in their own environment.
It runs on-premises or inside your VPC, including fully air-gapped setups, and includes basic object detection to complex instance segmentation, AI-assisted image and video labeling (e.g., SAM2), team and project management, quality control, and analytics tools.
Unlike CVAT Online, CVAT Enterprise gives teams in regulated or security-sensitive domains full control over their annotation environment. Teams can choose where the platform runs, define access and actions with SSO/LDAP and fine-grained RBAC, and track actions with audit logs.
They can tune storage and performance with GPUs and Kubernetes or Docker Compose, and integrate it into existing tools via an API-first, BYOM-friendly architecture. Because deployment is containerized, teams can start with a single node and scale to multi-region topologies on their own schedule and change-control processes.
CVAT Enterprise Features
The platform can be completely white-labeled, making it a compliant internal annotation solution that integrates into an enterprise AI/ML stack.
Since CVAT offers private images, deployment runbooks, migration guidance, and support for self-hosted setups, teams can save up months that they would spend on building an internal tool from scratch. As a result, they can deliver high-quality training datasets to their model pipeline faster without compromising security or compliance.
CVAT Online or Enterprise: Which Setup is Right for You?
Let's examine real-world use cases to determine the most suitable platform for each. Use case
Use case #1: Sports performance analysis

Consider a sports analytics startup developing AI systems for analyzing professional sports performance. Their setup includes:
- 20-person distributed team without dedicated IT personnel
- All data is public sports footage, no privacy limitations
- Need global access to cloud infrastructure
- Frequent API integrations with existing sports platforms
- Budget constraints favor operational over capital expenditures
Recommended Solution: CVAT Online
CVAT Online fits the startup requirements, given the team’s distributed structure. Its collaborative features enable seamless annotation and review across time zones. Its scalable cloud infrastructure supports high volumes of sports footage without local IT resources. Through the REST API, the team can integrate CVAT with analytics platforms, like Hudl, Tableau, and Stats Perform, to automate task creation and data export.
The team can also link CVAT to sports machine learning (ML) models, like a ball trajectory predictor or pose estimation model, using AI agents to automatically create initial labels. This setup, combined with built-in automation tools, delivers speed-to-value without the on-premises overhead essential for startups and fast-moving teams.
Use case #2: Medical device vision system
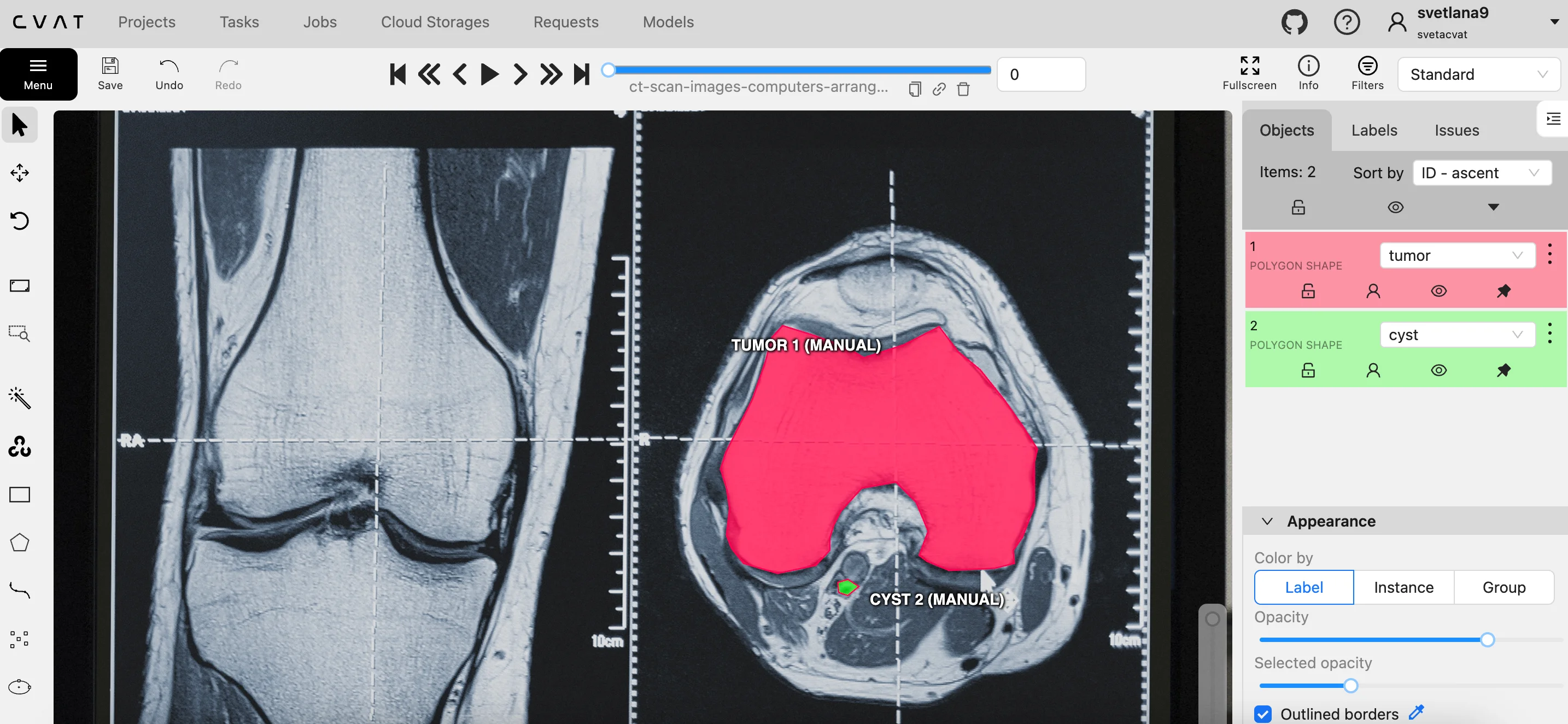
Now, let’s consider a mature medical device manufacturer developing computer vision systems for surgical robots. Their setup includes:
- 80-person R&D team managing sensitive patient data
- Strict HIPAA and FDA compliance requirements
- Need for complete control over system updates
- Custom integration with hospital systems
- Air-gapped development environment
Recommended Solution: CVAT Enterprise
Due to strict regulations on medical devices and surgical videos, annotation must occur in a controlled environment. For this reason, CVAT Enterprise is the best solution, as it keeps all data inside the company’s infrastructure, ensuring full ownership and compliance with FDA and HIPAA standards.
For large R&D teams (50+ users), Enterprise is more cost-effective than CVAT Online, as the total ownership cost decreases with more users. Besides security, the platform lets the team manage upgrade cycles (important for clinical trials relying on stable APIs) and deploy custom ML pipelines directly into the annotation process. A multi-node setup can support hundreds of users if the team grows, and integration capabilities ensure CVAT Enterprise works smoothly with existing hospital systems in an air-gapped environment.
Use case #3: Computer vision research institute

Finally, let’s look at a leading research institute expanding its computer vision program. Their setup includes:
- Initially, 8 researchers working on public datasets
- Growing to a 30+ team with government and industry contracts
- Mix of public and confidential research data
- Varying security requirements for each project
- Need for custom annotation tools in specialized research
Recommended Solution: CVAT Community as a trial, then switch to Online or Enterprise based on project needs.
Since the initial research involves only public datasets, the institute can start with CVAT Community, the free, open-source version of CVAT from which both platforms originated. CVAT Community provides access to the core platform’s toolset, so researchers can test everything from basic bounding boxes to advanced automation workflows without any initial expense.
As grant funding comes through and the team expands beyond basic research projects, they can choose the setup that suits their needs.
CVAT Online is valuable for collaborative projects where multiple labs need to annotate datasets simultaneously. CVAT Enterprise is ideal for medical research involving patient tissue samples that require HIPAA compliance. This flexible approach ensures the institute never pays for excess infrastructure and each project gets the right tools, whether cloud-based collaboration for public marine biology datasets or secure systems for sensitive biomedical research.
Building Your Annotation Infrastructure Right From the Start
Building the right annotation infrastructure is a critical investment that can accelerate or hinder your AI development. To choose between a cloud-hosted or on-premises deployment (e.g. CVAT Online and Enterprise), follow these strategic steps:
- Assess Your Security Posture
- Audit your data sensitivity levels
- Review compliance requirements (HIPAA, GDPR, etc.)
- Map existing security protocols and gaps
- Evaluate Technical Requirements
- Calculate expected annotation volume
- Document integration requirements with existing ML pipelines
- Assess computing resources and scalability needs
- Consider Team Dynamics
- Map current and projected team size
- Analyze annotator geographical distribution.
- Review collaboration patterns and requirements
- Plan for Growth
- Project 12-month annotation volume
- Estimate team expansion
- Calculate total cost of ownership
Whether you choose CVAT Online for rapid deployment and scalability, Enterprise for control and customization, or other data annotation software, success lies in matching the platform to your team's needs and growth trajectory.
For more information about CVAT Online and Enterprise, visit docs.cvat.ai. For personalized deployment guidance, contact our team.
.webp)




.svg)
.png)

.png)









.png)