



Artificial Intelligence is only as good as the data it learns from. In the world of machine learning, “garbage in, garbage out” isn’t just a cliché, it’s a business risk. That's because poorly labeled data doesn’t just slow down your models; it can quietly sabotage entire AI initiatives.
This is where data annotation quality metrics like Precision, Recall, and Accuracy come in. Far more than academic formulas, these metrics help you avoid costly annotation errors, and produce the kind of ground truth data that keeps AI models reliable at scale.
For beginners, mastering these three concepts is a gateway into understanding both the performance of your models and the integrity of your training datasets.
What Are Data Annotation Quality Metrics?
Data annotation quality metrics provide a structured way to evaluate how well your data labeling efforts are performing. They highlight whether labels are consistent, comprehensive, and aligned with the ground truth needed for model training.
For annotation teams, these metrics act as both a diagnostic tool and a roadmap for improvement, ensuring that data quality issues are identified early.
Think of it like this. Whenever a job boils down to making repeatable decisions with verifiable outcomes, a human effectively functions like a classifier or detection model. That means we can evaluate the quality of those decisions with model metrics: precision (how often actions are right), recall (how many true cases we catch), and accuracy (overall hit rate).
Precision
Precision measures the proportion of correctly labeled items among all items labeled as positive, where "positive" refers to the items that the model has predicted as belonging to the target class (e.g., spam emails, diseased patients, or images containing a specific object). It serves as a measure of label trustworthiness, making it central to quality assurance in any annotation project.
It is measured through the following formula:
Precision = True Positives (TP) ÷ [True Positives (TP) + False Positives (FP)]
Example: Imagine you labeled 10 objects as cats, but only 8 truly are cats. Your precision is 80%, meaning 2 of your labels were false positives. Another thing to note, if you label 1 cat as a cat, the precision will be 100% even if you were unable to find 9 other cats.
Why It Matters: In the annotation process, high precision shows that annotators are applying labels accurately and avoiding unnecessary noise.
For tasks like autonomous vehicle perception, this translates into fewer mistakes (false positives) in detecting pedestrians, vehicles, or obstacles and greater trust in the models that guide navigation and safety decisions.
Recall
Recall measures the proportion of actual positive items that were correctly labeled. It reflects how complete your annotations are, ensuring important objects or signals are not overlooked during the annotation process.
It is measured through the following formula:
Recall = True Positives (TP) ÷ [True Positives (TP) + False Negatives (FN)]
Example: Suppose there are 10 cats in an image, butand you labeled only 8 of them. Your recall is 80%, meaning 2 cats were missed.
Why It Matters: High recall indicates that annotators are capturing the majority of relevant items, reducing the risk of missing critical data.
In fields like autonomous vehicles or sentiment analysis, missing positive cases can severely undermine model performance and introduce hidden data quality issues.
Accuracy
Accuracy measures the overall proportion of correctly labeled items, including both true positives and true negatives, across the entire dataset. A true negative refers to an item that is not the target class and is correctly left unlabeled. For example, if you are labeling cats, a dog that remains unlabeled counts as a true negative.
Overall, accuracy provides a broad view of data annotation quality but can sometimes mask problems when working with imbalanced classes.
It is measured through the following formula:
Accuracy = (True Positives (TP) + True Negatives (TN)) ÷ (TP + TN + False Positives (FP) + False Negatives (FN))
For clarity, a true negative refers to an item correctly left unlabeled—e.g., when labeling “cats,” a dog that is not labeled counts as a true negative.
Example: If you label 100 items and 90 of them are correct, whether labeled or unlabeled, your accuracy is 90%. However, this might hide issues.
For instance, in object detection , a model might only detect 90 out of 100 objects (10 false negatives) and mislabel another 10 (10 false positives), resulting in the same 90% accuracy. But that doesn’t reflect the underlying errors.
Why It Matters: Accuracy gives a quick, high-level snapshot of annotation performance, but it can be misleading if one class dominates the dataset.
In highly imbalanced scenarios, like when one class intentionally makes up 99% of examples, skipping annotations for rare classes won’t drastically hurt overall accuracy, yet the resulting dataset can be highly unreliable. To get a clearer picture, accuracy should be paired with class-level metrics like precision and recall for each category.
Connecting the Metrics
Precision, Recall, and Accuracy each highlight different aspects of data annotation quality.
- Precision emphasizes trustworthiness, showing whether labels avoid unnecessary false positives.
- Recall emphasizes completeness, ensuring important objects or signals are not missed.
- Accuracy offers a big-picture view, showing the overall correctness of annotations.
Used together, these metrics provide a balanced perspective on how well your annotation process is performing and create the foundation for annotation QA, linking day-to-day labeling decisions to long-term model performance.
Why These Metrics Matter for Annotation QA
Formulas alone don’t capture the real value of Precision, Recall, and Accuracy. Their importance lies in how they connect day-to-day labeling decisions with long-term model reliability.
Direct Impact on Model Performance
Annotation quality metrics directly determine whether an AI system performs reliably in production. Precision, Recall, and Accuracy quantify how annotation decisions ripple through the entire ML pipeline, exposing weaknesses before they undermine results.
When these metrics are ignored, the consequences quickly surface in real-world applications:
- Low Precision → Too many false positives. In retail and ecommerce, this could mean mistakes in product classification, shelf monitoring, logo detection, and attribute tagging for catalogs.
- Low Recall → Missed signals. In autonomous vehicles, failing to detect pedestrians or traffic signs poses serious safety risks.
- Misleading Accuracy → Inflated performance. In sentiment analysis, accuracy may appear high simply because neutral reviews dominate, while misclassified positives and negatives go unnoticed.
By monitoring these metrics, data scientists and annotation teams can identify weaknesses in the annotation workflow early. This ensures training data does not silently introduce bias, inflate the error rate, or degrade model performance.
Consistency and Objectivity
High-quality data annotation is not just about labeling correctly; it’s about labeling consistently across annotation teams, projects, and time.
Without consistency, even well-labeled data can become unreliable, creating hidden biases that degrade model performance.
Precision, Recall, and Accuracy provide the objective lens needed to measure and maintain this consistency. These metrics reduce reliance on subjective reviewer opinions and bring structure to quality assurance.
Key ways these metrics improve consistency include:
- Standardizing Quality Checks → Metrics provide a common benchmark for all annotators, ensuring alignment with the intended annotation scheme.
- Reducing Subjectivity → Instead of relying on gut feeling, teams can use numbers to decide whether an annotation meets the gold standard.
- Comparing Performance → Metrics reveal differences in accuracy between annotators or teams, highlighting where additional QA steps or manual inspections are needed.
- Enabling Reproducibility → With consistent measurement, results can be validated across projects, supporting reproducibility checklists and reducing the risk of data drift.
By embedding these metrics into the annotation workflow, organizations gain both transparency and control, making data annotation quality measurable, repeatable, and scalable.
Ground Truth Validation
Even with strong annotation processes, you need a reliable way to measure new data against a gold standard dataset.
This is where Precision, Recall, and Accuracy become essential. They provide the framework for comparing fresh annotations to trusted ground truth labels, ensuring that new data is not drifting away from established quality benchmarks.
Ground truth validation acts as a safeguard, keeping the annotation process aligned with project goals.
Key benefits of applying metrics to ground truth validation include:
- Error Detection → Quickly identifies false positives and false negatives in new annotations.
- Confidence Intervals → Provides reliable quality estimates, ensuring that data annotations meet required sample sizes for validation.
- Bias Monitoring → Highlights systematic issues, such as ambiguous annotation guidelines or skill gaps among annotators.
- Long-Term Quality Control → Detects data drift by checking if new labels remain consistent with established ground truth data.
- Specification Validation → Reveals gaps or ambiguities in the data annotation specification itself, helping teams improve guidelines and reduce repeated errors.
By embedding ground truth validation into the annotation workflow, teams transform QA from a one-time checkpoint into an ongoing quality management process that scales with industry-level AI applications.
How CVAT Online & Enterprise Helps You Measure These Metrics
Both CVAT’s SaaS and on-prem editions elevate annotation QA from manual guesswork to a streamlined, metrics-driven workflow. Built with high-scale, mission-critical applications in mind, it empowers teams with automated tools, modular validation options, and analytics that map directly to precision, recall, and accuracy.
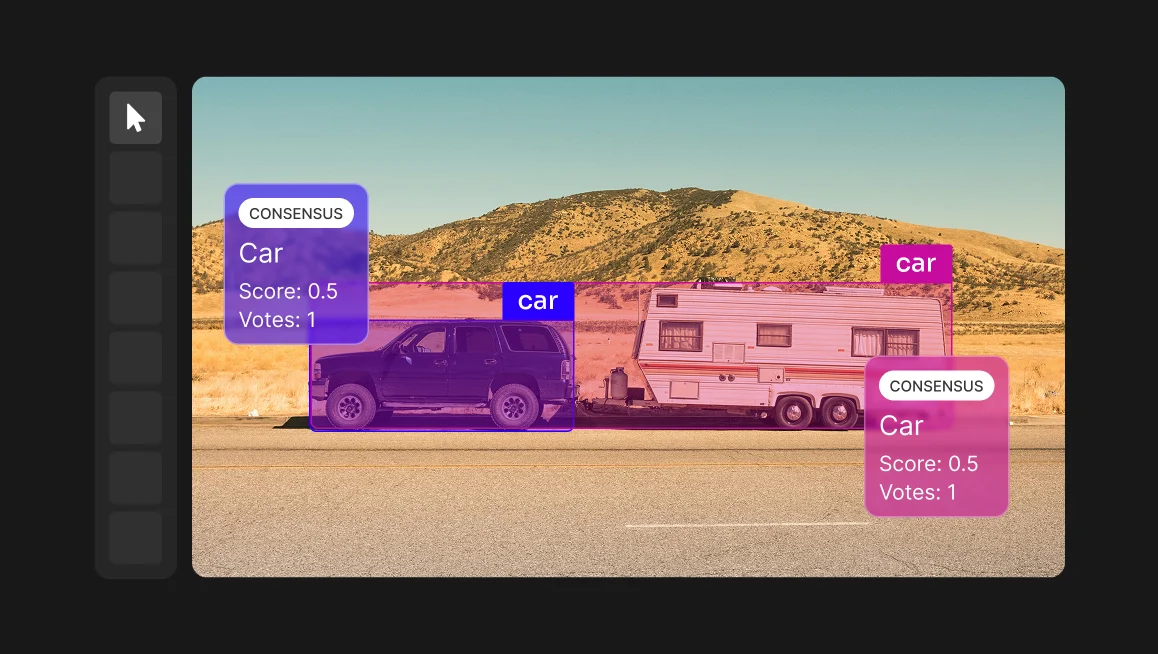
Consensus-Based Annotation
CVAT Enterprise enables the creation of Consensus Replica jobs, where the same data segment is annotated by multiple people independently.
These replica jobs function just like standard annotation tasks: they can be assigned, annotated, imported, and exported separately.
Why it Matters:
- Reduces Bias & Noise: By merging multiple perspectives, consensus helps eliminate outlier annotations and noise.
- Improves Ground Truth Reliability: Ideal for validating especially important samples within your dataset.
- Cost-Efficient Quality Control: Achieve robust ground truth with minimal additional annotation workload.
Consensus matters because high-quality machine learning models require trusted data to benchmark against. When ground truth annotations are unavailable or too costly to produce manually, consensus provides a practical path forward. By merging multiple annotations with majority voting, CVAT creates reliable ground truth that strengthens precision, recall, and accuracy scores in automated QA pipelines.
Learn more about consensus-based annotation here.
Automated QA Using Ground Truth & Honeypots
CVAT Enterprise enables automated quality assurance through two complementary validation modes: Ground Truth jobs and Honeypots.
Ground Truth jobs are carefully curated, manually validated annotation sets that serve as reliable reference standards for measuring accuracy. Honeypots build on this by embedding Ground Truth frames into regular annotation workflows without the annotator’s awareness, enabling ongoing quality checks across the pipeline.
The process of using this in CVAT is simple and scalable:
- A Ground Truth job is created within a task, annotated carefully, and marked as “accepted” and “completed,” after which CVAT uses it as the quality benchmark.
- In Honeypot mode, CVAT automatically mixes validation frames into annotation jobs at task creation, allowing continuous and unobtrusive QA sampling.
By comparing annotator labels against the trusted Ground Truth, CVAT calculates precision, recall, and accuracy scores automatically. This ensures quality is monitored in real time while reducing the need for manual spot checks, giving teams confidence in both speed and consistency at scale.
Learn more about automated QA with ground truth and honeypots here.
Manual QA and Review Mode
CVAT also includes a specialized Review mode designed to streamline annotation validation by allowing reviewers to pinpoint and document errors directly within the annotation interface.
Why It Matters:
- Focused Error Identification: The streamlined interface ensures that annotation flaws aren’t overlooked amidst complex tools.
- Structured Feedback Loop: QA findings are clearly documented and addressed systematically through issue assignment and resolution.
- Improved Annotation Reliability: By resolving human-reported mistakes, your dataset’s precision, recall, and overall trustworthiness are actively enhanced.
This mode elevates quality assurance beyond metrics, adding a human-in-the-loop layer for nuanced judgment.
Learn more about Manual QA and Review Mode in CVAT Enterprise here.
Summary & Takeaways
Precision, Recall, and Accuracy are more than academic metrics, they are the backbone of annotation quality assurance.
Together, they provide a balanced view of trustworthiness, completeness, and overall correctness in labeled data. High annotation quality directly translates into more reliable, fair, and high-performing AI systems, reducing costly errors and mitigating risks like data drift.
If you want to track and measure annotation quality at scale, CVAT provides the consensus workflows, automated QA, and analytics dashboards to make it happen.
Create a free CVAT Online account and see how we make training data more trustworthy, annotation teams more efficient, and AI models more reliable. Or, contact our sales team, if you want to try CVAT's QA features on your server.





.svg)
.png)

.png)









.png)