



Far too often, AI and ML projects begin with a model-first mindset. Teams dedicate talent and compute into tuning architectures and experimenting with deep learning techniques, while treating the dataset as fixed.
But this quickly leads to a painful realization. All that time you spent and all those GPUs you utilized to build the model is often worthless, because model performance is impacted less by design and more by the quality of the labels.
This is where data-centric AI changes the conversation. Instead of assuming data is static, it treats annotation quality (consistent & accurate labels), dataset creation, and ongoing curation as the real drivers of reliable outcomes.
Data-Centric AI vs. Model-Centric AI: Understanding the Difference
AI has long been built on a model-centric foundation in which researchers optimized architectures and fine-tuned parameters while treating datasets as static. That mindset produced progress in controlled benchmarks, but it often fails in production.
What is Model-Centric AI?
Model-centric AI is the traditional way many teams have tried to improve artificial intelligence systems.
Progress in this model-centric era was possible largely because massive datasets like ImageNet became available, enabling deep learning models to achieve breakthroughs despite imperfections in the data.
Some common traits of a model-centric approach include:
- Focusing on algorithm tweaks, not annotation quality
- Relying on compute power rather than improving training data
- Producing models that look strong in testing but fail under distribution shift
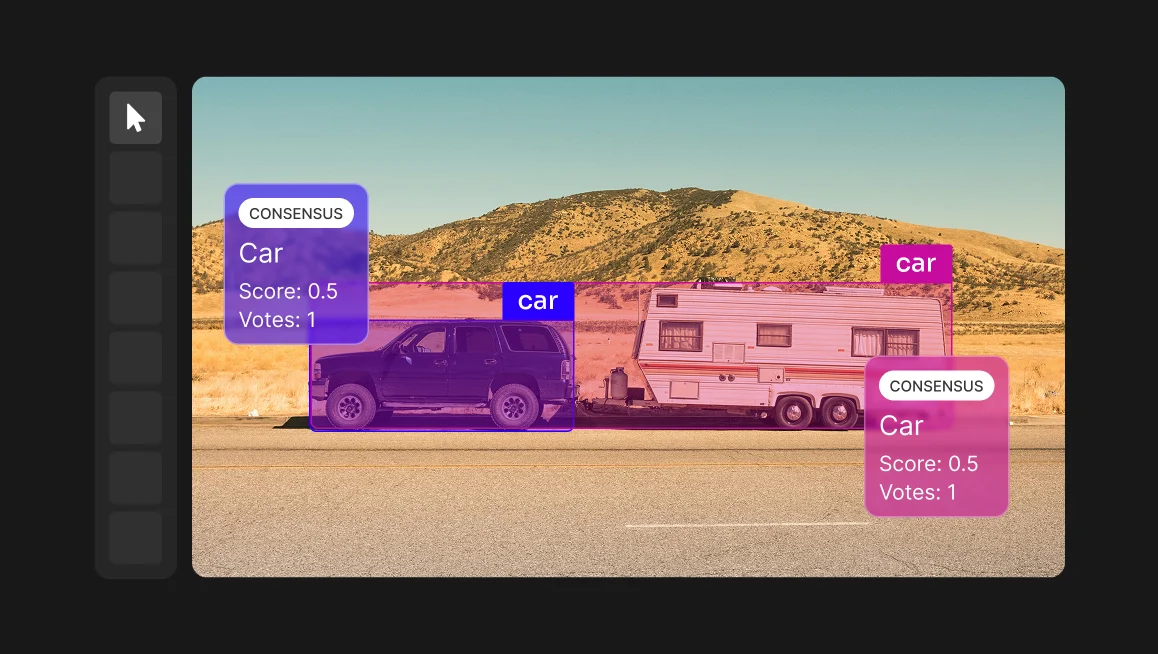
One key thing to note in model-centric AI is that data is treated as fixed, so whatever annotations exist are simply taken as-is. The downside of this approach is that in real-world computer vision tasks, datasets are rarely clean. In computer vision applications, for example, label errors, class imbalance, and noise in the dataset often cause failures.
A good illustration of these failures comes from medical image classification.
In datasets like OrganAMNIST and PathMNIST, researchers found that mislabeled images and class imbalance significantly lowered accuracy. This resulted in the model failing to distinguish between known conditions, which is especially harmful in healthcare settings.
Because of that, a shift is underway to a data-centric approach, which prioritizes annotation quality and dataset curation to provide more sustainable results.
What is Data-Centric AI?
Data-centric AI flips the priority, and instead of pushing models harder, it focuses on improving the dataset itself.
In data-centric AI, datasets are never fixed. Labels are audited, refined, and expanded to capture real-world variation. Subtle issues, like a scratch on a phone screen or a flaw in a medical device, are annotated precisely so they are not missed in deployment.
The advantage is that models trained on curated, high-quality data perform more reliably. They continue to work when real-world data looks different from the training data, reduce false rejections in inspection tasks, and achieve higher accuracy even in smaller data regimes.
Some common traits of a data-centric approach include:
- Prioritizing annotation accuracy and consistency across annotators
- Using active learning to surface uncertain samples for review
- Applying confident learning to detect and correct mislabeled data
- Treating data curation and dataset creation as ongoing, iterative processes
- Comparing datasets over time to measure progress in quality
In short, data-centric AI does not replace models but strengthens them. By prioritizing annotation quality instead of model performance, organizations create a stronger foundation for their AI models.
We recommend watching this video from Andrej Karpathy for added information.
Why Label Quality Often Beats Model Complexity
The contrast between model-centric and data-centric AI makes one thing clear: model performance ultimately depends on the quality of the labels it learns from.
This is because every AI system is only as strong as the data it learns from. While deep learning and advanced model architecture get attention, the reality is simple: if the training data is flawed, performance will suffer.
High-quality AI models depend on accurate labels and the quality of the images themselves. Poor image resolution, inconsistent samples, or unrepresentative datasets can weaken even the strongest models.
At CVAT, we focus on delivering precise annotations, while our partners like FiftyOne help teams select and curate the right data, ensuring that both images and labels contribute to stronger, more reliable AI systems.
Garbage Labels = Garbage Predictions
When annotations are incorrect, the model has no way to understand it is incorrect, so mislabeled or inconsistent data becomes baked into the predictions. This means a model trained on poor labels doesn’t just perform badly, it scales those mistakes across every deployment.
In computer vision tasks, these consequences are costly. For example, a mislabeled defect in a medical device inspection dataset can lead to false rejections, while confusing scratches with cracks in consumer electronics creates unreliable quality checks.
This is why no amount of deep learning complexity or hyperparameter tuning can undo bad data. Poor labels also increase the risk of overfitting, where a model learns noise instead of useful patterns.
High-Quality Labels Enable Reliable Feedback Loops
If bad labels lock errors into every prediction, high-quality annotations do the opposite. They create a foundation for models to improve. When labels are consistent and precise, they allow models to signal where they are uncertain, enabling teams to act on that feedback.
This is where feedback loops become powerful, as accurate datasets make it possible to:
- Run active learning to identify ambiguous samples for re-labeling
- Apply confident learning to detect hidden annotation mistakes
Each cycle of annotation, model training, and review builds stronger data assets, which means that instead of scaling mistakes, teams scale improvements. The result is an AI system that adapts better to distribution shifts, reduces false rejections in inspection tasks, and delivers more trustworthy outcomes in production.
Practical Steps to Improve Labeled Data Quality
If poor labels create unreliable models and high-quality labels enable feedback loops, the obvious question is, “How can you improve your data label quality?”
Well, it often comes down to an ongoing process of review, refinement, and curation. To get started, here are three practical steps any team can take.
1 - Use Active Learning to Target Low-Confidence Labels
If annotation errors are the root of unreliable AI, the solution lies in focused review. The key here is targeting the data labels most likely to contain errors.
This may sound like a challenging manual process, but with CVAT, teams can integrate active learning to automatically surface low-confidence samples for re-labeling. CVAT also takes this one step further by:
- Flagging low-confidence samples generated by model outputs or heuristic checks
- Providing “Immediate job feedback” via validation‑set (ground truth) jobs to catch errors early.
These practices help teams surface and correct mistakes efficiently, making human effort count where it matters most.
2 - Balance and Expand The Dataset
Even perfectly labeled data loses value if one category dominates. This is because class imbalance creates blind spots that models can’t recover from.
CVAT helps by making it straightforward to ingest new data into active projects. You can import full datasets or annotation files, including images, videos, and project assets, directly in the UI, then continue labeling within the same workspace.
If your imbalance involves spatial understanding, CVAT also supports 3D point cloud annotation with cuboids, so you can increase coverage for classes that are underrepresented in 3D scenarios like robotics or logistics.
3 - Track Progress Through Accurate Analytics
Improving annotation quality only matters if you can measure it. Without reliable metrics, teams can’t see whether label consistency is improving, class balance is shifting, or error rates are dropping.
This lack of visibility makes it difficult to justify investments in annotation or to understand why models still fail in production.
Thankfully, CVAT provides built-in analytics and automated QA to make progress transparent and actionable. These include:
- Ground truth jobs and auto-qa tools to compare annotations against reference subsets and catch errors early
- Analytics dashboards to monitor annotation speed, class distribution, and annotator agreement over time
By embedding measurement into everyday workflows, CVAT turns datasets into evolving assets.
Data-Centric AI Helps You Get the Most from Your AI Investments
The reality of artificial intelligence is clear: most failures don’t come from model design, they come from inaccurate data.
And while chasing improvements through a model-centric approach of grid search, hyper parameter tuning, and ever-larger architectures may boost results on benchmarks, it rarely solves real-world problems caused by poor label quality.
This is why a data-centric approach is more sustainable. By investing in annotation quality, ongoing data management, and techniques like data augmentation or active learning, teams strengthen their foundation and avoid scaling mistakes into production.
With CVAT, you can put a data-centric approach into practice. From annotation to data management and quality measurement, CVAT gives your team the tools to fix label errors, improve datasets, and build AI systems that actually perform in the real world.
Want to see how CVAT Works? Try CVAT Online, CVAT Enterprise, and the CVAT Community version now.





.svg)
.png)

.png)









.png)