


Most computer vision projects don’t actually fail because of the model architecture. They stall because teams hit an invisible wall trying to source high-quality training data. This is particularly true in semantic segmentation, which is the process of assigning a specific class label to every individual pixel in an image.
Because semantic segmentation relies on these high-fidelity, pixel-level labels to define the world, there is no room for the "close enough" approach used with bounding boxes. In this workflow, every single pixel must be accounted for, because even minor inconsistencies or "noisy" labels in your training set will directly degrade your model’s precision and its ability to generalize in the real world.
This makes your dataset selection a critical early decision that directly impacts performance. If the dataset's labels are misaligned, your model will never achieve the "pixel-perfect" accuracy required for production-grade AI.
What Is Semantic Segmentation and How Is It Used in Computer Vision?
To understand why high-quality data is the primary bottleneck, we first need to define the task.
Semantic segmentation is the process of partitioning an image into meaningful regions by assigning a specific class label to every individual pixel. Unlike other computer vision tasks that provide a general summary, semantic segmentation delivers a complete, pixel-by-pixel map of an environment.
In practice, this allows computer vision systems to understand the exact shape and boundaries of objects. It is used in high-precision applications like autonomous driving, where a car must distinguish between the "drivable surface" of a road and the "non-drivable" sidewalk , or medical imaging, where surgeons need to identify the exact margins of a tumor.
Here is how it differs from the standard tasks you likely already know:
- Image Classification: The model outputs a single label for the entire image, such as "Street Scene". It identifies what is in the photo but provides no information on location.
- Object Detection: The model outputs rectangular bounding boxes around specific objects. It identifies where a car is, but the box includes "noise" like bits of the road or sky in the corners.
- Semantic Segmentation: The model outputs a dense pixel mask where every pixel is labeled. In the car example, every pixel belonging to the car is labeled "car," while the surrounding "noise" pixels are labeled "road" or "sky". Note: All objects of the same class share the same label.
- Instance Segmentation: Like semantic segmentation, this provides pixel-level masks, but it treats multiple objects of the same class as distinct individual entities (e.g., "Car 1," "Car 2").
- Panoptic Segmentation: This is the most complete version, combining semantic and instance segmentation. It provides unique IDs for individual objects ("things") while also labeling amorphous backgrounds like grass or sky ("stuff").
How Semantic Segmentation Datasets Are Structured and Used
When building a dataset for semantic segmentation, a raw image (the visual data captured by a camera or sensor) is only the starting point. To be "production-ready," that image must be paired with one or more segmentation masks that provide the ground truth for every pixel.
The Relationship Between Images and Masks
In tasks like object detection, the "labels" are simply coordinates for a bounding box. However, because semantic segmentation requires defining the exact shape of an object, the labels must be as high-resolution as the image itself.
Instead of a single text file with coordinates, a semantic segmentation dataset typically consists of:
- The Raw Image: Standard visual data, such as an RGB photo.
- The Segmentation Mask: A pixel-perfect "map" (usually an indexed PNG or grayscale image) where the value of each pixel represents a specific Class ID rather than a color. For example, in a medical dataset, a pixel value of "1" might represent a tumor, while "0" represents healthy tissue.
- Multiple Masks (Optional): In complex projects, a single image may have multiple mask files to separate different categories of labels or to manage instance-level data.
The Role of Specialized Annotation
These masks are not generated automatically and are the result of a rigorous annotation process. Because the model learns the spatial relationship between visual textures (like the edge of a road) and the labels in the mask, the two files must be perfectly synchronized.
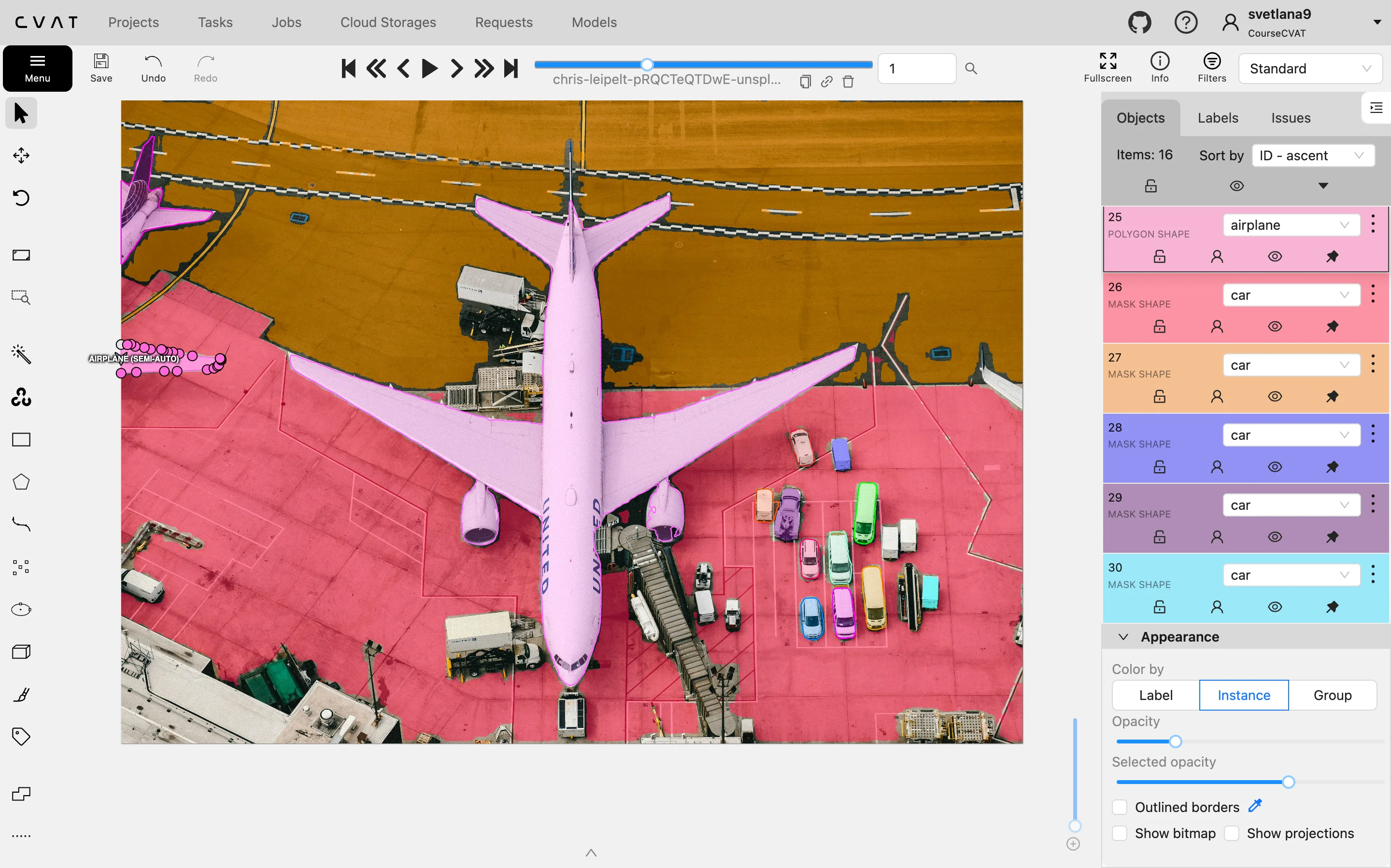
To create these high-fidelity datasets, teams use specialized annotation tools like CVAT. Instead of manually coloring millions of pixels, annotators use these tools to draw precise polygons (connected dots) around objects.
The software then converts these shapes into the dense, pixel-by-pixel masks required for training, ensuring the sharp object boundaries necessary for production-grade AI.
Common Semantic Segmentation Dataset Formats
To ensure your data is compatible across different training frameworks (like PyTorch, TensorFlow, or Detectron2) you need to use the following standardized technical formats.
- Indexed PNGs: These are preferred because they are lightweight and preserve exact integer values for every pixel. Unlike JPEG, they don't suffer from "compression artifacts" that could accidentally shift a pixel's label from "road" to "sidewalk" at the boundary.
- Class ID Mappings (JSON): Because a model only sees numbers (0, 1, 2), a companion JSON file acts as the "legend". It maps those integers to human-readable categories, such as {"7": "road", "8": "sidewalk"}.
- Polygon Metadata: Most annotators don't draw pixel-by-pixel. They draw polygons (a series of connected dots), which are easier to edit. Tools like CVAT then convert these polygons into the dense pixel masks required for model training.
By standardizing these formats early in the pipeline, teams prevent "data rot," ensuring that masks created today remain fully interoperable with future model architectures or different training workflows as the project scales.
Training, Benchmarking, and Fine-Tuning
A dataset’s role changes depending on where you are in the development lifecycle.
Training: This is the "heavy lifting" phase where the model consumes thousands of image-mask pairs to learn the foundational features of a scene.
Benchmarking: This acts as a standardized test to measure your model's real-world readiness. Teams use structured public datasets like Cityscapes or COCO to run "test sets," comparing their model's Mean Intersection over Union (mIoU), a metric that measures how well the predicted mask overlaps with the ground truth, against global State-of-the-Art (SOTA) performance.
Fine-Tuning: In production environments, few teams build from scratch. Instead, they take a "foundation model" already pre-trained on a massive, general-purpose dataset (like ADE20K) and specialize it on their own niche, structured data.
This structured lifecycle allows teams to leverage the broad knowledge of public datasets while using their own custom-labeled masks to push past the "performance ceiling" and achieve production-grade accuracy.
4 Common Datasets for Semantic Segmentation Compared
While many public datasets exist, the following options have become the industry standard.
Cityscapes Dataset

The Cityscapes Dataset is arguably the most influential benchmark for urban scene understanding and autonomous driving. Recorded across 50 different cities, it provides a diverse look at high-resolution street scenes captured in various seasons and daytime weather conditions.
What makes Cityscapes a "gold standard" is the sheer complexity of its labels. It doesn’t just identify objects, it captures the intricate interactions between vehicles, pedestrians, and infrastructure in dense urban environments.
Key Features:
- Dual Annotation Quality: The dataset includes 5,000 frames with "fine" pixel-level annotations and an additional 20,000 frames with "coarse" (rougher) polygonal labels.
- High-Resolution Data: Images are typically captured at 2048 x 1024 resolution, providing the granular detail necessary for identifying small objects like traffic signs or distant pedestrians.
- Comprehensive Class List: It features 30 distinct classes grouped into categories like flat (road, sidewalk), human (person, rider), and vehicle (car, truck, bus, etc.).
- Benchmark Leaderboard: It maintains a global State-of-the-Art leaderboard where models like VLTSeg and InternImage-H currently push Mean IoU scores above 86%.
A notable example is NVIDIA’s Applied Deep Learning Research team, which utilized Cityscapes to benchmark architectures derived from DeepLabV3+, achieving top-tier performance by optimizing how the model extracts hierarchical information from complex urban landscapes.
ADE20K Dataset

The ADE20K Dataset is the gold standard for large-scale scene parsing and indoor/outdoor environmental understanding. Spanning over 25,000 images, it provides a densely annotated look at complex everyday scenes with a massive, unrestricted open vocabulary.
While Cityscapes focuses strictly on the road, ADE20K challenges models to understand the entire world, from the layout of a kitchen to the architectural details of a skyscraper.
Key Features:
- Exhaustive Dense Annotation: Unlike datasets that only label foreground objects, every single pixel in ADE20K is assigned a semantic label, covering 150 distinct object and "stuff" categories (like sky, road, and floor) in its standard benchmark.
- Hierarchical Labeling: It is one of the few datasets to include annotations for object parts and even "parts of parts," such as the handle of a door or the cushion of a chair.
- Extreme Diversity: The dataset captures 365 different scene categories, ensuring models are exposed to a wide variety of lighting conditions, spatial contexts, and object occlusions.
- Competitive Benchmark: The MIT Scene Parsing Benchmark, built on ADE20K, is a primary proving ground for global SOTA models like BEiT-3, which currently pushes Mean IoU scores to approximately 62.8%.
A notable use case example is the development of Microsoft’s BEiT-3 (Image as a Foreign Language), which utilized ADE20K to demonstrate the power of unified vision-language pre-training. By benchmarking on ADE20K’s complex scene parsing task, the team achieved state-of-the-art performance, proving that their model could successfully "read" and segment the intricate relationships between hundreds of object classes in a single frame.
PASCAL VOC Segmentation Dataset

The PASCAL VOC (Visual Object Classes) Dataset is the classic, foundational benchmark for object recognition, detection, and semantic segmentation.
While it is significantly smaller than modern massive datasets like COCO, its high-quality, standardized annotations have made it the primary entry point for researchers and engineers testing new model architectures.
Key Features:
- Diverse Object Categories: The dataset covers 20 distinct classes, categorized into vehicles (cars, buses, trains), household items (sofas, dining tables), animals (dogs, cats), and persons.
- Standardized Evaluation Metrics: It popularized the Mean Intersection over Union metric, providing a robust mathematical way to compare the accuracy of different segmentation models.
- Beginner-Friendly Structure: Its XML annotation format and relatively small size of roughly 11,500 images in the 2012 version make it compatible with almost all standard computer vision tools and ideal for educational tutorials.
- Historic SOTA Benchmark: It has hosted annual challenges that led to the development of legendary architectures like Faster R-CNN, SSD, and DeepLab, which continue to influence the industry today.
A notable example is the evaluation of DeepLabV3+, one of the most successful semantic segmentation models to date. The research team used PASCAL VOC to demonstrate the model's superior ability to capture multi-scale contextual information through various convolutions, achieving a Mean IoU of 82.1% and setting a new standard for how models refine object boundaries.
COCO Stuff Dataset

The COCO Stuff Dataset is an extension of the massive Microsoft Common Objects in Context (COCO) benchmark, designed to provide a "panoptic" or complete view of an image.
While the original COCO focuses on countable objects “things” with distinct shapes like cars, people, or dogs, COCO Stuff adds labels for "stuff," which refers to amorphous background regions like grass, sky, and pavement.
By labeling both objects and their background surroundings, it forces models to understand how a "thing" relates to the "stuff" around it. Which means recognizing, for instance, that a metal object is likely an airplane if it is surrounded by "sky," but likely a boat if it is surrounded by "water".
Key Features:
- Massive Category Count: The dataset features 172 distinct categories, including the original 80 "thing" classes from COCO and 91 "stuff" classes, providing a comprehensive vocabulary for daily scenes.
- Dense Pixel-Level Annotations: Every pixel in its 164,000 images is accounted for, offering a total of 1.5 million object instances across diverse, complex environments.
- Complex Spatial Context: It captures the intricate relationships between foreground objects and background materials, such as a train (thing) traveling on a track (stuff) beneath a bridge (stuff).
- Universal Benchmark: It is the primary training ground for "universal" architectures like Mask2Former and OneFormer, which currently push Mean IoU (mIoU) scores to approximately 45% on the full 172-class challenge.
A notable use case for the COCO stuff dataset is the development of Facebook AI’s Mask2Former, a "universal" segmentation model that achieved state-of-the-art results by training on COCO Stuff.
How to Choose the Right Semantic Segmentation Dataset to Start With
Now that we’ve highlighted four options, we want to mention that there is no one single best dataset.
The "best" dataset isn't necessarily the largest one, but the one that most closely mirrors the visual domain and label granularity of your production environment.
When evaluating your options, use these five criteria to determine if a dataset aligns with your project goals:
- Domain Alignment: Does the imagery match your camera's perspective? A model trained on the "bird’s-eye view" will struggle to understand the "first-person" perspective of an autonomous vehicle in Cityscapes.
- Label Complexity vs. Scale: Are you prioritizing a massive variety of classes (like ADE20K’s 150 categories) or a smaller, more precise set? High label complexity often requires more training data to achieve convergence.
- Annotation Fidelity: Does your use case require "pixel-perfect" boundaries (e.g., medical surgery) or are "coarse" polygonal labels sufficient for general object localization?
- Licensing and Commercial Usage: Many public datasets are restricted to non-commercial research (Creative Commons BY-NC). Always verify that the license allows for private or commercial redistribution.
- Data Diversity: Ensure the dataset covers the "long-tail" scenarios of your industry, such as varied weather, lighting conditions, or rare object occlusions.
Challenges with Common Semantic Segmentation Datasets
Public datasets are essential for research, but they are rarely "plug-and-play" solutions for production-grade AI. Scaling a model from a benchmark to a real-world application reveals several structural and technical hurdles that teams must navigate.
Inconsistent Class Definitions
There is no universal standard for "what is a car" or "where does a sidewalk end." For example, the Cityscapes dataset might include a vehicle's side mirrors in its mask, while COCO Stuff might exclude them.
When teams attempt to combine multiple datasets to increase their training pool, these conflicting definitions create "label noise" that confuses the model and degrades its accuracy.
Annotation Noise and Boundary Ambiguity
Even in "gold standard" datasets, human error is inevitable. At the pixel level, determining the exact boundary between a tree's leaves and the sky is subjective.
This ambiguity leads to "fuzzy" edges in the ground truth, making it difficult for the model to learn sharp, precise object boundaries, which is a major hurdle in fields like medical imaging or high-precision manufacturing.
The High Cost of Pixel-Level Annotation
While bounding boxes for object detection typically take only a few seconds per object, the labor involved in semantic segmentation is on a completely different scale.
To understand the sheer effort required, look at the Cityscapes dataset where labeling a single, complex urban image with high-quality, pixel-level annotations takes an average of 1.5 hours. For a dataset of 5,000 images, that translates to 7,500 hours of manual tracing, a workload that causes many projects to stall before they even reach the training phase.
This massive time investment is why industry leaders are pivoting toward AI-assisted workflows.
Instead of drawing every boundary by hand, teams are using platforms like CVAT to automate the process. By leveraging integrated AI and foundation models (like SAM) to generate initial masks, CVAT allows users to annotate data up to 10x faster than traditional manual tracing.
Creating and Building Your Own Semantic Segmentation Datasets
To move from raw benchmark scores to a high-performing model in specialized environments, professional teams follow an iterative data-centric AI pipeline.
Taxonomy & Requirement Engineering
Before a single pixel is labeled, you must define the ground truth. This involves creating an exhaustive annotation manual that dictates how to handle edge cases, like whether a "person" includes the backpack they are wearing or how to label semi-transparent objects like glass. Inconsistency in this step is the #1 cause of model failure.
Strategic Data Sourcing & Curation
A production dataset requires a "Golden Distribution", or a strategic balance of data to ensure the model is both highly accurate in common scenarios and resilient when facing rare ones. To achieve this, your dataset must consist of:
- A Massive Foundation: This is your "bread and butter" data, consisting of representative, everyday scenarios that the model will encounter most frequently.
- Targeted Diversity: To prevent the model from overfitting to a single environment, you must intentionally source data across different sensors, geographical locations, and times of day.
By curating a balanced dataset, you ensure the model can handle the "long-tail" scenarios of your industry, such as varied weather, lighting conditions, or rare object occlusions.
Production-Scale Annotation
This is where the bulk of the work happens. To stay efficient, teams use AI-assisted labeling (like SAM, Ultralytics YOLO, or other models) to generate initial masks. This allows human annotators to act as "editors" rather than "illustrators," drastically increasing throughput.
Multi-Stage Quality Assurance (QA)
Production-grade data requires a "Reviewer-in-the-loop" system to ensure the high precision required for semantic segmentation.
Because even minor label inconsistencies can degrade model performance, teams should implement a multi-layered validation process that includes:
- Manual Review: Every segmentation mask is checked by a second, more senior annotator to verify boundary accuracy and class consistency.
- Consensus Scoring: In high-stakes fields like medical imaging or autonomous driving, multiple annotators label the same image independently. Their results are compared, and only masks with a high degree of agreement are used for training.
- Honeypots: Teams insert "gold standard" images with known, perfect labels into the workflow to secretly test annotator accuracy and maintain high standards throughout the project.
- Automated Validation: Using programmatic checks to ensure that all pixels are accounted for and that no impossible class combinations exist (e.g., a "car" label appearing inside a "sky" region).
Looking to Turn a Dataset Into a Production-Ready Model?
Bridging the gap between a common dataset and a high-performance specialized one requires a platform built for precision and scale.
Whether you are a solo researcher or an enterprise-scale engineering team, CVAT provides the infrastructure to build your own "gold standard" datasets through:
- AI-Assisted Efficiency: Leverage 2025's most advanced foundation models, including SAM 3, to automate the heavy lifting of pixel-level tracing.
- Scalable Enterprise Workflows: Manage global teams with robust role-based access controls, detailed project analytics, and multi-stage review loops that ensure every mask is verified before it hits the training server.
- Seamless Integration: Export your data in any industry-standard format (from Indexed PNGs to COCO JSON) to maintain total interoperability with your existing PyTorch or TensorFlow pipelines.
Plus, CVAT is available in two different formats to fit your needs.
With CVAT Online, you can start your project immediately in your browser without managing any infrastructure. CVAT Online gives you instant access to SAM 3 for text-to-mask segmentation and SAM 2 for automated video tracking. With native, browser-based integrations for Hugging Face and Roboflow, you can pull in pre-trained models and push your annotated datasets to your training pipeline without a single line of infrastructure code.
With CVAT Enterprise, you can bring the power of CVAT to your own infrastructure. Benefit from dedicated AI Agents that run on your own GPUs, custom model hosting for proprietary taxonomies, and advanced Quality Assurance (QA) tools, including honeypots and consensus scoring, designed for the most demanding production-scale workflows.




.svg)
.png)

.png)









.png)