


Video annotation is the backbone of many modern artificial intelligence (AI) and machine learning (ML) systems, yet it remains one of the most labor-intensive tasks in the AI lifecycle. If you’ve ever manually drawn bounding boxes frame-by-frame, you know the struggle: it is painstakingly slow and prone to human error, often leading to inconsistent tracks that require hours of cleaning.
Thankfully, there is a solution: ML/AI models that can automate the heavy lifting and allow you to annotate entire video sequences with just a few clicks with frame-to-frame consistency.
In this article, we’ll explore the top-performing models for different video tracking tasks, from high-speed object detection to pixel-perfect segmentation, and show you how to choose the right one for your specific use case.
The Hierarchy of Video Tracking Tasks
Before picking a model, you must determine which tracking sub-task fits your data. Most video annotation projects fall into one of two categories based on how the objects are identified and followed:
Single-Object Tracking (SOT) & Video Object Segmentation (VOS)
Single-Object Tracking (SOT) and Video Object Segmentation (VOS) focus on maintaining a relentless lock on one specific target provided by the user. SOT provides a focused bounding box, while VOS generates a high-fidelity, pixel-level mask that adapts to the object's changing shape.
- Best For: Scenarios requiring extreme precision, such as robotic surgery, medical imaging, or analyzing the complex movements of mechanical parts.
- Example: VOS is often used to track the exact geometry of a surgical instrument or a robotic gripper. By using models like XMem or the newly released SAM 3, researchers can maintain publication-quality masks across long video sequences, ensuring the model captures complex shape analysis that a simple bounding box would miss.
Multi-Object Tracking (MOT)
Multi-Object Tracking (MOT) is designed to detect and track every instance of a specific class, like every vehicle in a traffic feed, by generating bounding boxes with persistent ID numbers that follow each unique object throughout the video.
- Best For: High-throughput video annotation where you need to quantify large numbers of moving parts.
- Example: High-throughput aerial datasets often use MOT to handle hundreds of moving targets. A prime example is the M3OT dataset (Nature, 2025), which provides over 220,000 bounding boxes for multi-drone tracking in RGB and Infrared modalities, labeled with CVAT
Pipeline Anatomy: How Tracking Works in Practice
Before diving into specific models, it is helpful to understand the tracking-by-detection pipeline, which is the industry standard for most production environments. This workflow typically involves three distinct stages:
- Per-frame Detector: A model like YOLOv12 or RT-DETR scans individual frames to identify objects.
- The Tracker: A secondary algorithm, such as ByteTrack or DeepSORT, links those detections across frames to maintain unique IDs.
- Optional Segmentation Head: If your task requires more than a box, models like XMem or SAM 3 are used to generate precise pixel-level masks.
Now that we’ve broken down the architecture, let’s look at some specific MOT, SOT, and VOS models.
The Three Main Types of Models for Video Tracking
1. Multi-Object Tracking (MOT) Models via "Tracking-by-Detection"
When your goal is tracking every vehicle on a highway or every person in a retail store, the industry standard is the tracking-by-detection pipeline.
In this workflow, a high-performance detector identifies objects in each frame, and a separate association algorithm (like ByteTrack or BoT-SORT) links those detections across time.
Here are the SOTA detection models used to power these pipelines:
YOLO Family (YOLOv12)
The YOLOv12 family represents the cutting edge of real-time object detection, evolving the "You Only Look Once" legacy into an attention-centric powerhouse. It is designed for speed, scanning entire video frames in a single pass to identify objects instantly rather than piece-by-piece.
Key aspects of this model include:
- Primary Function: Single-step frame scanning for instantaneous object labeling.
- Practical Use: Essential for high-FPS footage like drone or automotive video.
- Standout Feature: Uses "global attention" to understand how objects relate within a scene.
This balance of velocity and contextual intelligence makes it the premier choice for high-speed annotation pipelines.
RT-DETR (Real-Time DEtection TRansformer)

RT-DETR (Real-Time DEtection TRansformer) is the first transformer-based detector to achieve real-time speeds, providing a high-accuracy alternative to the traditional YOLO family. By treating detection as a direct set-prediction problem, it avoids the typical complexities of grid-based scanning.
Key aspects of this model include:
- Primary Function: Utilizes "object queries" to predict all objects simultaneously rather than searching the image grid-by-grid.
- Practical Use: Ideal for production environments like autonomous robotics or surveillance where precision is non-negotiable but lag is not an option.
- Standout Feature: Eliminates the Non-Maximum Suppression (NMS) bottleneck, ensuring smooth, consistent performance with no post-processing delays.
This end-to-end architecture delivers a superior balance of accuracy and stability for complex, high-stakes visual tasks.
ByteTrack

ByteTrack is a high-performance association algorithm that acts as the essential "glue" of a tracking pipeline, linking detections across frames to maintain consistent identities. It is renowned for its efficiency, relying on motion and geometry rather than heavy visual computation.
Key aspects of this model include:
- Primary Function: It "rescues" low-score or blurry detections that other trackers might discard, ensuring tracks don't break when objects become fuzzy.
- Standout Feature: Extremely lightweight because it tracks based on logic and movement patterns rather than "remembering" what an object looks like.
It is currently the industry standard for real-time applications like traffic monitoring or crowd counting when paired with a YOLO detector.
DeepSORT

DeepSORT is a sophisticated tracking model that incorporates deep learning to "recognize" objects through unique visual profiles.
Key aspects of this model include:
- Primary Function: Creates a unique visual "fingerprint" for every object, allowing the model to recognize them even after they disappear and reappear.
- Practical Use: The premier choice for complex scenes with long occlusions, such as tracking a specific person walking behind obstacles in a security feed.
- Standout Feature: Excels at re-identification (Re-ID), making it highly robust against identity swaps during long periods where an object is hidden.
While more computationally demanding, it provides superior reliability in crowded environments where objects frequently overlap.
2. Single-Object Tracking Models (SOT)
These models are designed to "lock onto" a single target and follow it relentlessly, regardless of how it moves or how the camera shifts.
OSTrack
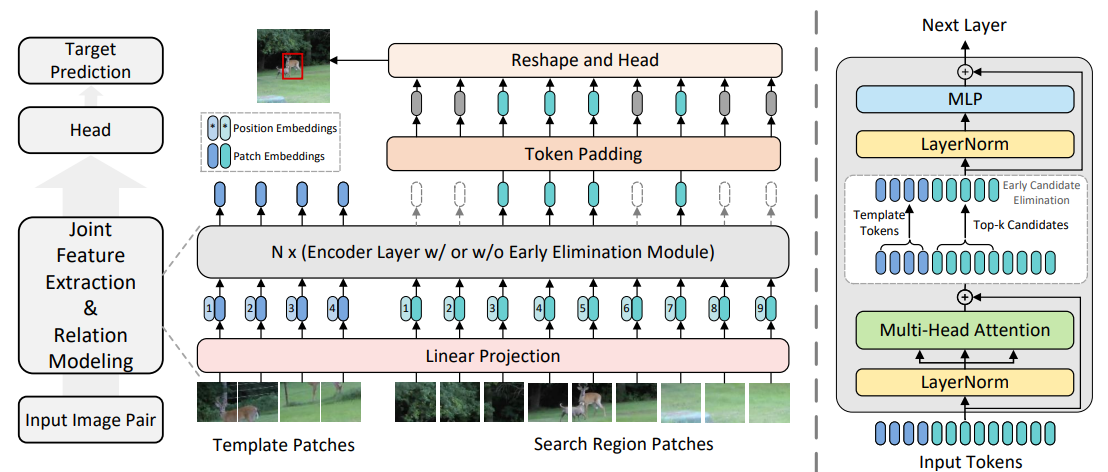
OSTrack is a cutting-edge "one-stream" tracker that utilizes a transformer architecture to unify feature extraction and relation modeling into a single step.
Key aspects of this model include:
- Primary Function: Integrates feature learning and matching in parallel, allowing the model to understand the target within its environment more effectively than traditional two-stream pipelines.
- Practical Use: The current "State-of-the-Art" for benchmarks like LaSOT and GOT-10k, making it perfect for high-value targets like drones or wildlife.
- Standout Feature: Extremely efficient single-stream approach that delivers faster convergence and higher accuracy than older Transformer trackers.
The focused architecture provides relentless accuracy for single-target missions where precision is the absolute priority.
TrackingNet
TrackingNet is a reliable framework and large-scale benchmark designed to bridge the gap between academic theory and real-world performance.
Key aspects of this model include:
- Primary Function: Focuses on generic object tracking by following a target's position, scale, and motion dynamics with high temporal consistency.
- Practical Use: Widely used in industrial robotics and high-speed assembly lines where a camera must track a specific part without fail.
- Standout Feature: Offers "reasonable speed," providing a balanced performance that runs effectively on standard hardware without requiring elite-level GPUs.
By prioritizing robustness over sheer complexity, TrackingNet remains a staple for industrial-grade tracking where reliability is king.
3. Video Object Segmentation (VOS) Models
When bounding boxes aren't enough, VOS models provide "pixel-level" masks, allowing you to track the exact shape and boundaries of an object as it moves.
XMem (eXtra Memory Network)
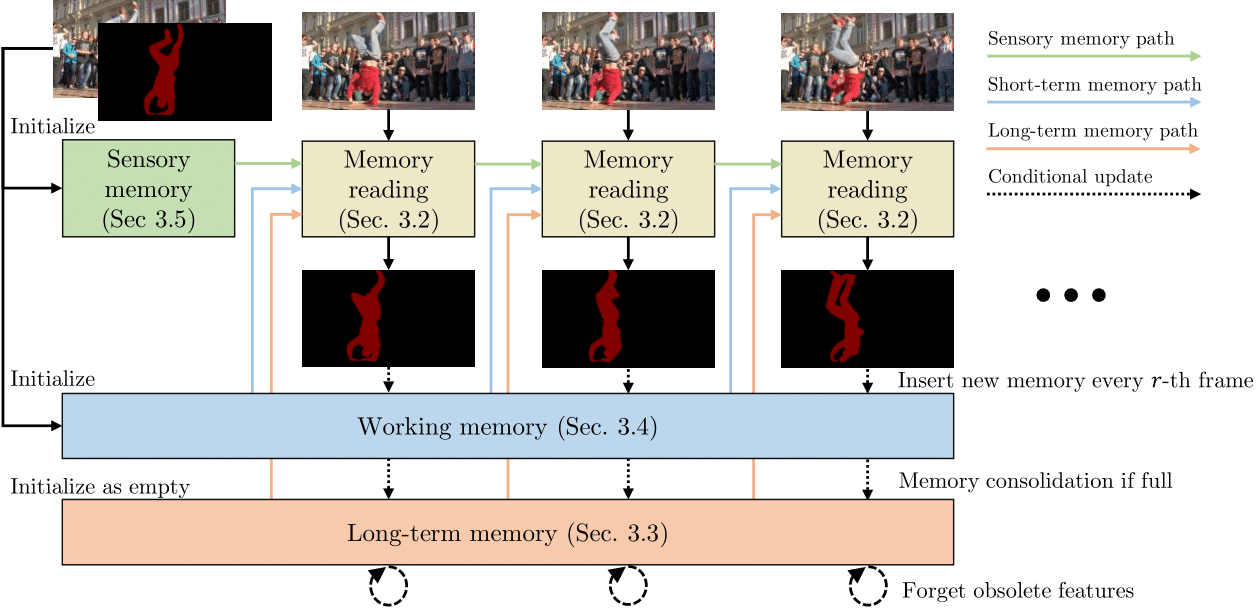
XMem (eXtra Memory Network) is a high-fidelity segmentation model designed to maintain mask quality over long video sequences. It solves the problem of "forgetting" by utilizing a sophisticated memory architecture to store object features over time.
Key aspects of this model include:
- Primary Function: Utilizes a long-term memory module to maintain mask quality and identity even in very long videos.
- Practical Use: The go-to model for producing publication-quality masks for high-end visual analysis and research.
- Standout Feature: Extremely consistent across long sequences, preventing the "drift" or loss of detail that plagues simpler models.
This focus on long-term temporal consistency makes XMem the premier choice for complex projects where every pixel matters from the first frame to the last.
4. Promptable Segmentation & Interactive Tracking (SAM / SAM 2 / SAM 3)
The SAM Family (Segment Anything Models) represents a shift toward "promptable" AI, allowing you to track and segment any object with a simple click or text command. These foundation models eliminate the need for project-specific training, working "out-of-the-box" for almost any category.
Key aspects of these models include:
- Primary Function: SAM 3 introduces "promptable concept segmentation," enabling users to track objects using descriptive text rather than manual clicks.
- Practical Use: SAM 2 and 3 natively handle video tracking, drastically reducing user interactions for complex VOS.
- Standout Feature: SAM 3 features native video handling and advanced identity retention to prevent the model from confusing similar objects.
By moving from frame-by-frame clicking to high-level concept tracking, the SAM family has set the new standard for interactive video annotation efficiency.
How Tracking and Segmentation Models Are Evaluated
For high-throughput annotation projects, the industry relies on three core metrics to measure how well a tracker maintains order in a crowded scene.
1. Multi-Object Tracking Metrics
MOTA (Multi-Object Tracking Accuracy)
This is the most established metric, focusing heavily on detection quality. It counts three types of errors: False Positives (ghost detections), False Negatives (missed objects), and Identity Switches (when ID 1 suddenly becomes ID 2).
While useful, MOTA is often criticized because it prioritizes finding every object over keeping their identities consistent for long periods.
IDF1 (ID F1 Score)
Unlike MOTA, IDF1 focuses almost entirely on identity consistency. It measures how long a tracker can follow the same object without an error, making it the superior metric for tasks like long-term surveillance or player tracking in sports.
It is calculated by finding the longest possible match between a predicted track and the ground truth across the entire video.
HOTA (Higher Order Tracking Accuracy)
Developed to solve the "tug-of-war" between MOTA and IDF1, HOTA is now considered the most balanced SOTA metric.
It splits evaluation into three distinct sub-scores: Detection Accuracy (DetA), Association Accuracy (AssA), and Localization Accuracy (LocA). This allows engineers to see exactly where a model is failing, whether it's failing to "see" the object or failing to "link" it across frames.
2. Video Object Segmentation (VOS) Metrics
When evaluating pixel-level masks instead of bounding boxes, researchers use the J and F metrics popularized by the DAVIS Challenge and YouTube-VOS benchmarks.
Region Similarity (J / Jaccard Index)
J is essentially the Intersection over Union (IoU) for masks, which measures the static overlap between the predicted pixels and the ground truth pixels. A high J score means the model has captured the bulk of the object's body accurately.
Contour Accuracy (F - Measure)
While J looks at the "body," F looks at the "edges". It evaluates how precisely the model has traced the boundary of the object. This is critical for high-fidelity tasks like rotoscoping, where a mask that is "mostly correct" but has jagged, incorrect edges is unusable.
How to Choose the Right Model For Your Use Case
Selecting the ideal model for video tracking involves balancing raw processing speed against the need for high-precision identification.
To do this, you must weigh critical factors such as real-time latency for high-speed feeds, identity persistence for crowded environments, and mask fidelity for complex scientific or medical data.
As a general rule of thumb, we suggest following these industry-standard pairings for your specific project:
- For real-time traffic or urban surveillance: Use YOLOv12 paired with ByteTrack to maximize frames-per-second while tracking hundreds of objects simultaneously.
- For crowded scenes with long occlusions: Use DeepSORT to leverage visual "fingerprints" that prevent ID switching when objects are temporarily hidden.
- For pixel-perfect masks and complex shape analysis: Use SAM 3 or XMem to achieve high-fidelity, consistent segmentation across long sequences.
- For tracking a single high-value target (e.g., a robot gripper): Use an OSTrack-style SOT model for a relentless, focused lock on one entity.
By prioritizing the correct architecture from the start, you ensure high-throughput consistency, reduce downstream errors in safety-critical scenarios, and establish a reliable foundation that scales as your dataset grows.
Where Models Can Still Struggle
Even though you choose an industry-standard model, you can still run into "edge cases" where the logic can falter. This can happen because even SOTA AI/ML models still struggle with:
- Occlusion: This occurs when an object is fully or partially hidden (e.g., a pedestrian walking behind a tree). While models like DeepSORT use visual "fingerprints" to recover these tracks, simpler models may lose the ID entirely.
- ID Switching: In crowded scenes, the model may confuse two similar objects, like two white cars and swap their unique ID numbers as they cross paths.
- Scale and Perspective Changes: Models often struggle when an object moves from the far background (appearing very small) to the close foreground (appearing very large), as the rapid change in pixel size can break the tracker’s "lock".
- Motion Blur: Fast movements or low-shutter-speed footage can cause objects to appear as a "smear," making it difficult for the detector to identify features and resulting in lost or erratic tracks.
How You Can Mitigate These Issues in Annotation
To address the inherent limitations of AI, you can apply these four mitigation strategies to your workflow:
1) Address Domain Shift through Strategic Data Selection
The Strategy: Use a mix of real-world "edge cases" and synthetic data to expose the model to the specific lighting, angles, and object scales of your project.
CVAT Advantage: Instead of starting from scratch, you can plug in specialized models from platforms like Roboflow or Hugging Face that are already pre-trained for niche domains like manufacturing or healthcare.
2) Implement a Human-in-the-Loop (HITL) Review
The Strategy: Use AI to do the first 80% of the work while humans handle the difficult 20%, specifically at points where objects overlap or disappear.
The CVAT Advantage: CVAT’s Track Mode uses powerful temporal interpolation. You only need to set "keyframes" before and after an occlusion, and CVAT automatically calculates the smooth path in between, significantly reducing manual frame-by-frame adjustments.
3) Leverage the Power of Fine-Tuning
The Strategy: Use a small, carefully curated subset of your own data to fine-tune a model, which "internalizes" the specific motion patterns of your targets.
The CVAT Advantage: CVAT allows you to export your corrected labels in dozens of formats (like YOLO or COCO) to immediately fine-tune your model. You can then re-upload your improved model via a custom AI Agent or Nuclio function to auto-annotate the rest of your dataset with much higher accuracy.
4) Identity Management & Track Refinement
The Strategy: In complex scenes, models often suffer from "ID switches" or "fragmented tracks" when objects cross paths. Instead of manually redrawing these, use a workflow that treats objects as continuous "tracks" rather than a collection of individual shapes.
The CVAT Advantage: If a model loses a track during a crowded scene, you can use CVAT’s Merge feature to unify separate fragments into a single, persistent ID. This, combined with the ability to "Hide" or "Occlude" shapes while maintaining the track’s metadata, ensures that your final dataset preserves the object’s identity from the first frame to the last.
It’s Never Been Easier to Integrate ML Video Tracking into Your Workflow
We are witnessing a significant shift toward unified and any-modality tracking models, with recent research, such as the "Single-Model and Any-Modality" demonstrating how general-purpose trackers can handle different tasks and sensor types (like RGB, Thermal, or Depth) within a single architecture.
The best part about this shift is that you don't need to rebuild your entire infrastructure or design a custom UI to start.
CVAT is designed to bridge the gap between cutting-edge research and production-grade annotation, allowing you to plug these advanced models directly into your existing workflow without writing a single line of interface code.
With our high-performance environment, you can deploy the industry's best models and manage them within a single, streamlined interface that includes:
- Native SAM 2 & SAM 3 Tracking: Leverage the world’s most advanced segment-and-track models integrated by default. Use built-in algorithms to automatically calculate the path of bounding boxes and masks between keyframes, drastically reducing manual clicks.
- Seamless Model Integration: Whether your model is a custom-built proprietary stack or a public favorite on Roboflow or Hugging Face, you can integrate it directly as an AI agent.
- Integrated Review & QA: Ensure data integrity with specialized workflows that allow human supervisors to quickly identify, "merge," and correct any model errors before they reach training.
If you’re ready to move on from the grind of manual tracking and start leveraging the latest in AI-assisted annotation, we have a solution that fits your needs:
Get started today with CVAT Online and begin labeling in seconds. CVAT Online gives you immediate access to SAM 2, SAM 3, and seamless integrations with Roboflow or Hugging Face directly in your browser.
Scale your production with CVAT Enterprise and bring CVAT to your own infrastructure. With CVAT Enterprise, you can deploy a secure, self-hosted instance with dedicated AI agents, custom model hosting, and full ecosystem integration for large-scale production.




.svg)
.png)

.png)









.png)