


The computer vision landscape is shifting from simple pattern recognition to deep, world-aware intelligence, defined by multimodal AI, 3D spatial mapping, and generative data pipelines that can simulate millions of miles of driving data or medical testing before a single prototype ever hits the road or the clinic.
In fact, we predict that in 2026, these technologies will empower a new wave of applications, from autonomous drones navigating dense urban forests to medical systems performing real-time 3D surgical mapping.
While we believe AI models will become more powerful next year, their performance is only as good as the information they learn from. That is why the industry is moving beyond simply "collecting" data and toward "curating" it with surgical precision.
Why the Quality of a Dataset Matters for Computer Vision Applications
Garbage in, Garbage Out
The ‘Garbage In, Garbage Out’ is a classic rule of computing, but in 2026, it is absolute.
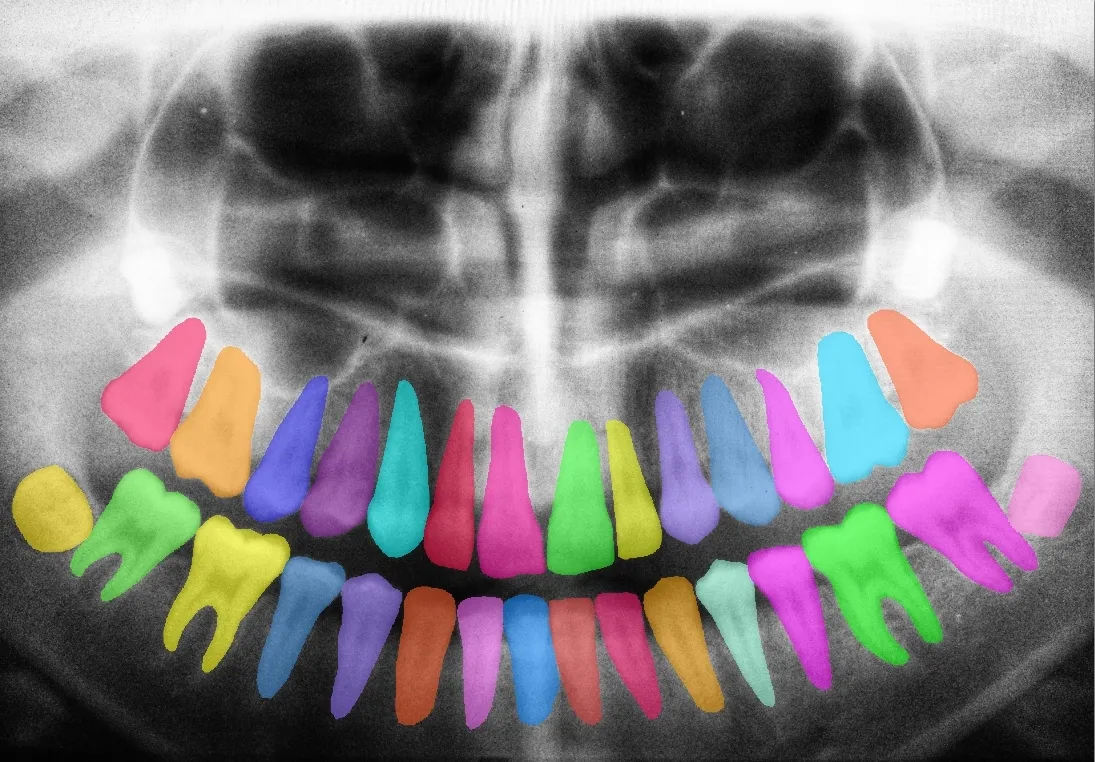
A model's performance is fundamentally tied to the precision of its labeled data, especially as we move toward pixel-perfect segmentation. In high-stakes fields like healthcare or autonomous driving, the margin for error is non-existent.
Even a 1% error in pixel-level labels can lead to catastrophic failures, such as a medical AI misidentifying a rare pathology or a navigation system miscalculating a curb's depth.
Mastering the "Hard Negatives" and Edge Cases
In the past, showing a model a thousand photos of a clear street was enough. Today, models must be robust against the unpredictable.
High-quality datasets must now include "hard negatives" and rare edge cases, like a stop sign partially obscured by a reflection, or a pedestrian in low-light conditions that break standard shape recognition.
Without these "long-tail" scenarios, a model remains a "fair-weather" pilot, unable to handle the beautiful messiness of real-world unpredictability.

Fairness and Representativeness
In 2026, quality data also needs fairness and representativeness. If a dataset lacks diversity, be it geographical, demographic, or environmental, the resulting AI will inevitably carry those biases into production.
High-quality data ensures that a vision system works as accurately in a rainy rural village as it does in a sunny tech hub, avoiding the algorithmic bias that can stall global innovation.
What Determines a Good Dataset?
As models transition from laboratory settings to high-stakes production environments, a high-quality dataset should have the following features.
Multimodal Integration
The dominant paradigm for 2026 AI systems is multimodality, which is the ability to process and generate synchronized data from diverse sources.
A superior dataset integrates various data streams together to provide a holistic view of a scene. By combining visual inputs with other sensory information, datasets enable models to achieve higher accuracy and robustness in complex real-life scenarios.
This is done by fusing multiple layers of information together, including:
- Synchronized Sensor Streams: Aligning data from RGB cameras, LiDAR, radar, and infrared sensors.
- Visual-Linguistic Pairs: Pairing images or videos with natural language descriptions for context-aware reasoning.
- Metadata Context: Adding non-visual data such as temperature, motion, or GPS to deepen a model's understanding.
A prime example of this is the nuScenes dataset, which revolutionized the field by providing synchronized data from a full sensor suite (6 cameras, 1 LiDAR, 5 RADAR), allowing models to "see" and "feel" the environment simultaneously across varying weather and lighting conditions.
Annotation Density and Precision
As computer vision applications move into high-stakes fields like healthcare and autonomous driving, the margin for error has effectively vanished. Precision is the bedrock of safety-critical AI, and in 2026, it is measured by ‘annotation density’, which is the amount of labeled data within a dataset.
This shift moves development away from simple bounding boxes toward pixel-perfect masks and 3D metadata that capture the entirety of a scene.
By increasing annotation density, teams can train models to recognize subtle features, such as the specific orientation of overlapping objects in a dense warehouse, which are critical for the next generation of "embodied" AI.
High-Resolution and Diversity
Diversity in a dataset is the primary defense against model bias and failure in production.
In 2026, a "good" dataset must represent the full spectrum of global reality, capturing variations that standard web-scraped data often overlooks. High-resolution imagery further supports this by allowing models to detect small or distant objects with the clarity required for precision tasks.
To ensure true representativeness, top-tier datasets focus on:
- Environmental Variation: Diverse weather conditions, lighting, and geographic locations, from urban tech hubs to rural villages.
- Demographic Representation: Balanced coverage across different ethnicities, ages, body types, and physical attributes.
- Long-Tail Scenarios: Intentional inclusion of rare edge cases and "hard negatives" that standard datasets typically miss.
The Cityscapes Dataset is a great example of capturing diverse data. This dataset provides high-resolution frames from 50 different cities in various weather conditions, specifically curated to ensure that urban driving models aren't just "overfit" to a single street or climate.

Clear Provenance and Compliance
In the current regulatory landscape, a dataset is only as valuable as its paper trail.
With the full enforcement of AI safety standards in 2026, clear provenance and legal compliance have become absolute business imperatives. When using a dataset, organizations must now prove not only what data powers their models, but exactly how it was collected, transformed, and authorized.
A compliant dataset in 2026 is defined by:
- Verifiable Lineage: A documented history of data transformations, algorithm parameters, and validation steps.
- Ethical Sourcing: Evidence of explicit consent from data rights holders and fair treatment of human annotators.
- Transparency and Auditability: Public summaries of training data sources and adherence to privacy regulations.
The risks of ignoring these standards are best illustrated by the LAION-5B dataset. Despite its unprecedented size, LAION-5B faced significant scrutiny and was temporarily removed from distribution after a report by the Stanford Internet Observatory (SIO) discovered over 3,000 instances of suspected Child Sexual Abuse Material (CSAM) embedded as links within the data. This controversy highlighted how a lack of rigorous filtering and provenance can expose organizations to severe legal and ethical liabilities.
As a result, the industry has shifted toward "vetted" datasets like DataComp-1B. Unlike its uncurated predecessors, DataComp-1B prioritizes transparent source tracking and rigorous filtering, ensuring that performance gains are matched by legal integrity.
What Are Some Computer Vision Datasets to Follow in 2026?
While we aren’t able to cover every new dataset in this blog, we did want to highlight a few that have caught our attention.
These were chosen specifically for their inclusion in top-tier 2025 conferences like CVPR and NeurIPS, and their focus on solving "frontier" problems, such as raw sensor processing, ultra-high-resolution reasoning, and fine-grained spatial logic, rather than simply iterating on older classics like COCO or ImageNet.
AODRaw

Key Details:
- Total Images: 7,785 high-resolution RAW captures.
- Annotated Instances: 135,601 instances across 62 categories.
- Atmospheric Diversity: Covers 9 distinct light and weather combinations, including low-light rain and daytime fog.
- Processing Advantage: Supports direct RAW pre-training to bypass ISP overhead.
AODRaw is a pioneering dataset designed for object detection, specifically targeting adverse environmental conditions.
This dataset is particularly interesting because it addresses the "domain gap" that often causes models trained on clear daylight images to fail when conditions turn poor. By training directly on unprocessed sensor data, AI can "see" through noise and lighting artifacts that would typically obscure critical objects.
For developers, AODRaw offers a unique chance to build a single, robust model capable of handling multiple conditions simultaneously. Instead of training separate models for day and night, this data provides the diversity needed for a truly universal perception stack.
XLRS-Bench
Key Details:
- Images Collected: 1,400 real-world ultra-high resolution images
- Image Resolution: Average of 8,500 x 8,500 pixels per image.
- Evaluation Depth: 16 sub-tasks covering 10 perception and 6 reasoning dimensions.
- Total Questions: 45,942 human-annotated vision-language pairs.
- Reasoning Focus: Includes tasks for spatiotemporal change detection and object motion state inference.
XLRS-Bench sets a new standard for ultra-high-resolution remote sensing (RS), designed specifically to evaluate Multimodal Large Language Models (MLLMs).
It boasts an average image size of 8,500x8,500 pixels, with many images reaching 10,000x10,000, roughly 10 to 20 times larger than standard benchmarks. This scale allows models to perform complex reasoning over entire city-level scenes rather than tiny, isolated crops.
What makes XLRS-Bench a "must-watch" is its focus on cognitive processes like change detection and spatial planning. It moves beyond simple object classification to test if an AI can understand "spatiotemporal changes," such as identifying new construction or inferring a ship's movement from its wake.
This is a massive leap forward for urban planning, disaster response, and environmental monitoring.
DOTA-v2.0
Key Details:
- Instance Count: Over 1.7 million oriented bounding boxes in DOTA-v2.0.
- Tracking Volume: 234,000 annotated frames across multiple synchronized views in MITracker.
- Geometric Precision: Uses 8 d.o.f. quadrilaterals for oriented object detection.
- Recovery Metrics: MITracker improves target recovery rates from 56.7% to 79.2% in occluded scenarios.
DOTA-v2.0 and the integrated MITracker framework provide the ultimate benchmark for detecting and tracking objects from aerial perspectives.
DOTA-v2.0 features 1.7 million instances across 18 categories, using "Oriented Bounding Boxes" (OBB) to capture objects like ships and airplanes at any angle. Meanwhile, MITracker enhances this by using multi-view integration to maintain stable tracking even when targets are temporarily occluded from one camera's view.
The core innovation here is the shift from 2D images to 3D feature volumes and Bird’s Eye View (BEV) projections. By projecting multi-camera data into a unified 3D space, the AI can "stitch together" a target's trajectory even through complex intersections or warehouse clutter.
This combined data power allows for "class-agnostic" tracking of 27 distinct object types, from everyday items to heavy machinery.
SURDS
Key Details:
- Total Instances: 41,080 training instances and 9,250 evaluation samples.
- Reasoning Categories: Covers depth estimation, pixel-level localization, and pairwise distance.
- Logical Tasks: Includes front–behind relations and orientation reasoning.
- Model Integration: Designed specifically to benchmark and improve fine-grained spatial logic in VLMs.
SURDS (Spatial Understanding and Reasoning in Driving Scenarios) is a large-scale benchmark designed to give Vision Language Models (VLMs) "common sense" in the physical world.
Built on the nuScenes dataset, it contains over 41,000 vision-question-answer pairs that test an AI’s ability to understand geometry, object poses, and inter-object relationships. It is the definitive test for whether an AI truly "understands" the road or is just memorizing patterns.
What makes SURDS fascinating is its focus on fine-grained spatial logic. Instead of just labeling a car, the model must answer questions about "Lateral Ordering" (which car is further left?) or "Yaw Angle Determination" (which direction is the truck facing?).
Surprise3D & Omni6D

Key Details:
- Query Scale: 200,000+ vision-language pairs and 89,000+ human-annotated spatial queries in Surprise3D.
- Object Diversity: 166 categories and 4,688 real-scanned instances in Omni6D.
- Capture Volume: 0.8 million image captures for 6D pose estimation.
- Reasoning Depth: Covers absolute distance, narrative perspective, and functional common sense.
Surprise3D and Omni6D represent the pinnacle of indoor 3D understanding, combining spatial reasoning with precise 6D object pose estimation.
The "object-neutral" approach in Surprise3D is a breakthrough because it forces AI to rely on geometric reasoning rather than semantic shortcuts.
For example, a robot might be asked to find "the item used for sitting" rather than a "chair," ensuring it truly understands functional properties and 3D layout. This is critical for "embodied AI" that must navigate and interact with messy, unfamiliar human environments.
Omni6D complements this by providing rich annotations including depth maps, NOCS maps, and instance masks across a vast vocabulary of 4,688 real-scanned instances. It uses physical simulations to create diverse, challenging scenes with complex occlusions and lighting.
Together, these datasets provide the foundation for robots to perform precise manipulations and navigate 3D spaces with unprecedented intelligence.
SA-1B (Segment Anything 1-Billion)
Key Details:
- Total Images: 11 million high-resolution, privacy-protected licensed images.
- Total Masks: Over 1.1 billion high-quality segmentation masks (the largest to date).
- Image Quality: Average resolution of 3300×4950 pixels, ensuring granular detail for small objects.
- Annotation Method: A three-stage "data engine" comprising assisted-manual, semi-automatic, and fully automatic mask generation.
- Global Diversity: Features images from over 200 countries to ensure broad geographical and cultural representation.
The SA-1B dataset is the foundational engine behind Meta AI’s Segment Anything Model (SAM). Released to democratize image segmentation, it moved the industry away from labor-intensive, task-specific training toward "zero-shot" generalization, which is the ability for a model to segment objects it has never seen before.
Because SA-1B is class-agnostic, it focuses on the geometry and boundaries of "anything" rather than a limited set of pre-defined labels.
How Can You Find Other Trending Datasets in 2026?
While the datasets we've highlighted are currently at the forefront of the industry, the computer vision field moves at breakneck speed.
By the time you’ve integrated one breakthrough, another is likely being presented at a conference or uploaded to a community hub. In 2026, staying ahead of the curve means knowing exactly where to look for the next wave of high-quality, long-tail data.
Here is how you can stay in the loop and find the latest trending datasets throughout the coming year.
Hugging Face & Kaggle: The Community Hubs
Hugging Face and Kaggle have become the "primary hubs" for trending open-source datasets and community-vetted benchmarks.
These platforms act as living libraries where researchers and developers upload their latest work, often accompanied by "dataset cards" that explain the provenance, ethical considerations, and intended use cases.
Kaggle, in particular, is invaluable for finding niche or competitive datasets that have been "stress-tested" by thousands of data scientists in real-world challenges.
To find new datasets here, you should leverage the "Trending" or "Most Downloaded" filters. On Hugging Face, the datasets library allows you to programmatically search for new uploads using specific tags like object-detection or multimodal.
Academic Portals: CVPR and WACV
For research-grade data that pushes the theoretical limits of AI, academic portals are your most reliable source.
Major conferences like CVPR 2026 and WACV 2026 (taking place in March 2026) are the launchpads for datasets that define state-of-the-art benchmarks. These datasets are typically released alongside peer-reviewed papers, ensuring they have undergone rigorous validation.
The best way to stay updated is to follow the CVF (Computer Vision Foundation) Open Access library. During conference weeks, you can search for "Dataset" in the paper titles to find the newest repositories.
Google Dataset Search: The Universal Index
If you are looking for data hosted across fragmented university, government, or specialized repositories, Google Dataset Search is an essential tool. It functions as a specialized search engine that indexes over 25 million datasets from publishers worldwide, making it the fastest way to discover data that might not be on the major social hubs.
To use it effectively, you can filter results based on last updated or usage rights (e.g., commercial vs. non-commercial). For example, searching for specific sensors or environments like "FMCW Radar datasets" or "Arctic urban driving" to find niche repositories hosted by academic institutions or government bodies that the broader AI community hasn't yet discovered.
Cloud Provider Libraries: AWS, Google Cloud, and Azure
For enterprise-level applications, exploring pre-curated collections from AWS, Google Cloud, and Microsoft Azure is highly recommended.
These libraries host massive, high-value datasets that are optimized for their respective machine learning pipelines, such as Amazon SageMaker or Google’s Vertex AI. These are often "industry-grade" sets, such as satellite imagery or large-scale medical archives, that would be too expensive for a single team to collect on their own.
You can access these via the AWS Open Data Registry, Google Public Datasets, or Azure Open Datasets. These providers frequently add new, ethically sourced collections that are compliant with global regulations.
Looking for a Platform to Create, Refine, and Manage Datasets?
While public datasets are an incredible resource for benchmarking and initial training, they eventually hit a ceiling. To achieve true competitive advantage and handle the specific "long-tail" scenarios unique to your business, your team must eventually move beyond open-source data and begin curating custom, proprietary datasets.
This is where CVAT becomes an essential part of your stack. Whether you are dealing with the multi-camera 3D views of Omni6D or the pixel-perfect requirements of AODRaw, CVAT provides a scalable, high-quality environment for the most complex segmentation workflows.
If you are a small team or a researcher looking to start annotating immediately with industry-leading tools, our cloud platform is the perfect place to begin.
For organizations requiring advanced security, custom deployments, and massive-scale collaboration, our enterprise solutions provide the control and power you need to manage your data at a global level.




.svg)
.png)

.png)









.png)