



Glance at any modern U.S city, and it’s easy to assume the era of the self-driving car has already arrived. We currently share the road with over 98 million vehicles with Advanced Driver Assistance Systems (ADAS) that can parallel park themselves, maintain perfect following distances, and even change lanes with the flick of a turn signal.
But this visible progress masks a significant reality: there is a massive technological canyon between the 'smart' driver-assist features of today and a fully automated society where the steering wheel is obsolete (which recognized brands like Rivian believe we can achieve by 2030).
This raises the question: how do we teach a machine to make that leap?
The answer lies in a process known as data annotation, which gives these autonomous vehicles the structured understanding they need to interpret every lane line, pedestrian, and unpredictable moment on the road.
The process involves training machine learning models on millions of real-world scenarios, which becomes the foundation for the autonomous vehicle’s (AV) ability to perceive, predict, and react to its surroundings with the split-second precision required to ensure safety.
However, achieving this level of precision is far from a simple labeling task.
The Unique Challenge of Annotating Data for Autonomous Vehicles
The unique difficulty of annotating for autonomous vehicles ultimately boils down to two distinct challenges: the unforgiving stakes of the operation and the complexity of the physical world.
The First Challenge: The Stakes
The first hurdle is that the margin for error is effectively zero. In a standard computer vision project, such as an app trained to identify a breed of dog, a mislabeled image is a minor inconvenience. In the context of autonomous driving, however, a few missing pixels can be catastrophic.
An AV cannot misjudge the distance to a nearby vehicle or miss a partially obscured stop sign hiding behind a tree without risking life-critical consequences. This requirement for absolute precision places an immense burden on annotators to be perfect, 100% of the time.

The Second Challenge: Data Diversity and Complexity
The second hurdle is the sheer chaos of the environment the vehicle operates in. Unlike a factory robot, a self-driving car must navigate a world filled with infinite variables.
This begins with geographic variance; road signs, lane markings, and traffic rules shift drastically from country to country, meaning a model trained in California might fail in Germany.
This complexity then extends to environmental conditions, where annotators must accurately label objects through heavy rain, blinding sun glare, or low-light night driving.
To make matters more challenging, teams must also solve "semantic ambiguity" (when something can have multiple interpretations). For example, if a truck is transporting six cars on a trailer, should the AI view that as one large truck or seven distinct vehicles? Or, how should the system interpret a construction zone where yellow tape supersedes the painted lane lines? Resolving these edge cases requires deep human judgment to ensure the AI understands not just what it sees, but what it means.
What Type of Data is Collected for Labeling?
Before a single label can be applied, the raw sensor data must be harvested from the real world. In the autonomous vehicle industry, this data generally flows from two distinct sources, depending on the maturity and scale of the project.
Field-Captured Data (Proprietary Fleets)
For industry leaders like Waymo or Tesla, data is collected via custom-built fleets of test vehicles. These cars are rigorous data-gathering machines, equipped with a calibrated array of sensors including LiDAR (for depth), high-resolution cameras (for color and context), and RADAR (for velocity).
- The Workflow: These vehicles are deployed into targeted environments, which are specifically chosen to capture "edge cases." A fleet might spend weeks driving through snowy neighborhoods in Detroit or navigating complex unprotected left turns in San Francisco.
- The Result: The car records every millisecond of the drive into raw log files. This ensures the engineering team owns the data and can hunt for specific scenarios, such as "pedestrians wearing dark clothes at night."

Open-Source and Ready-Made Datasets
Not every team has a fleet of 50 cars on the road. For researchers, startups, and benchmarking, the industry relies on high-quality, pre-recorded datasets released by major players or academic institutions.
- The Workflow: Instead of capturing the data themselves, teams download massive, curated libraries of sensor data. Notable examples include the Waymo Open Dataset, nuScenes (by Motional), or Argoverse.
- The Result: These datasets provide a standardized baseline, allowing engineers to train perception models on thousands of hours of verified driving scenarios without the overhead of managing a physical fleet.
Whether captured by a proprietary fleet or downloaded from an open repository, the output is the same: a massive, unorganized collection of sensor readings. To turn these raw logs into a driving intelligence, the data must be rigorously structured.
How Annotation Helps Make Sense of This Raw Data
Whether captured by a proprietary fleet or downloaded from an open repository, the initial data is often just a massive, unorganized collection of raw sensor readings. To turn these raw logs into driving intelligence, the data must be rigorously structured and annotated using the following techniques.
2D Bounding Boxes (Camera Data)
The most fundamental form of AV annotation starts with standard 2D camera images. In this workflow, annotators draw tight rectangular boxes around objects to establish their classification and position within the frame.
2D bounding boxes are critical for high-speed object detection and visual interpretation. Because cameras capture color and texture (which LiDAR lacks), this technique is essential for details that require visual confirmation.

Common AV applications for this data include:
- Object Classification: Teaching the system to instantly recognize different classes of actors, such as distinguishing between a cyclist, a courier on a scooter, and a pedestrian.
- State & Attribute Recognition: Identifying visual cues that geometry cannot reveal. This includes reading the text on a speed limit sign, detecting if a vehicle’s brake lights are on, or identifying the color of a traffic signal.
While 2D boxes are excellent for identifying what an object is, they have a distinct limitation: they track pixels on a flat screen (X and Y coordinates) but cannot calculate physical distance (Z-axis). To solve this lack of depth and provide spatial context, teams must transition to 3D point cloud annotation.
3D Point Cloud Annotation
To solve the lack of depth in 2D images, teams rely on LiDAR. In this technique, annotators work within a 3D Point Cloud (a spatial map made of laser reflections) to draw 3D cuboids around objects.
Unlike a simple flat box on an image, a 3D cuboid defines an object’s exact length, width, height, and its orientation. This tells the AI not just where a car is, but exactly which way it is facing.
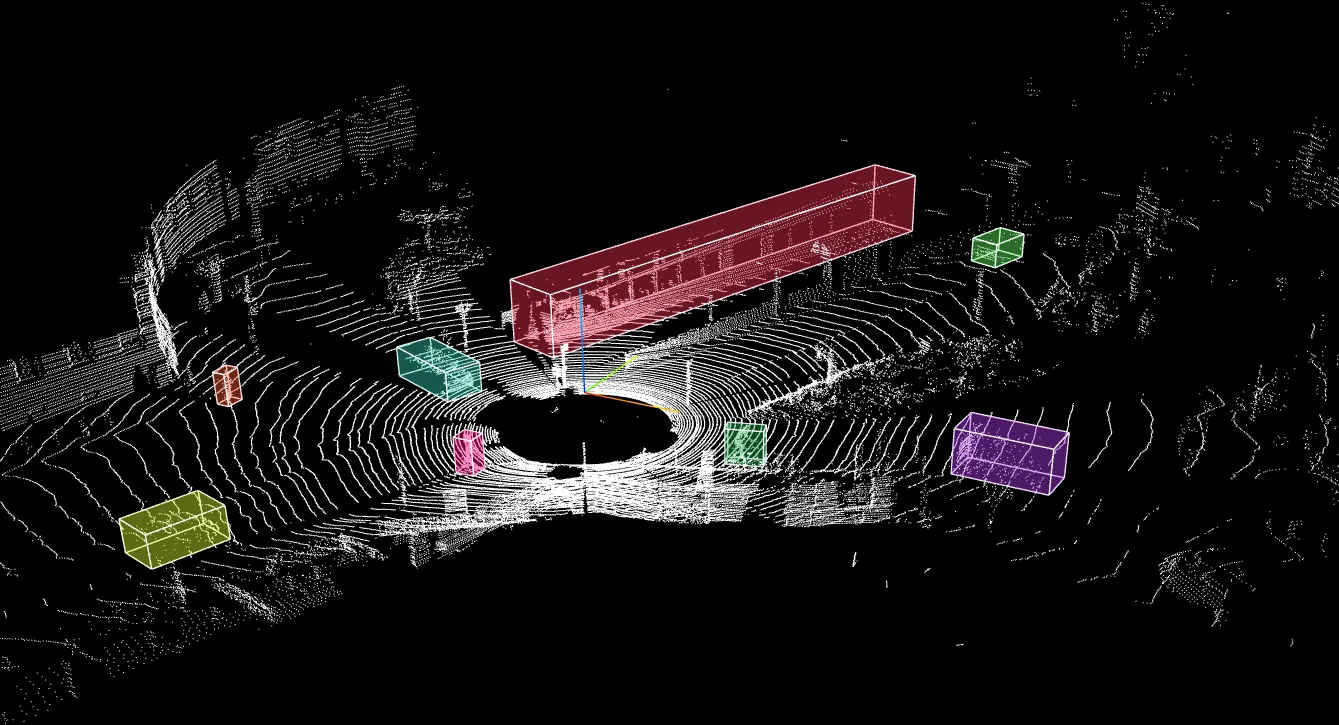
Common AV applications for this data include:
- Precise Object Localization: Distinguishing between a pedestrian on the curb versus one stepping into the street with centimeter-level accuracy.
- Trajectory Prediction: Using the orientation of the cuboid to calculate the future path of moving vehicles.
By transforming a chaotic cloud of dots into structured, measurable objects, this process provides the spatial awareness necessary for the vehicle to brake or swerve safely in complex environments.
Sensor Fusion Annotation (Multi-Modal Labeling)
One of the most complex tasks for an annotator is making sense of a sparse 3D point cloud. A cluster of laser dots might look like a bush, a rock, or a crouching pedestrian. It is often impossible to tell from geometry alone.
To solve this ambiguity, teams use sensor fusion annotation. In this workflow, the annotation platform synchronizes high-resolution 2D RGB camera feeds with the raw 3D LiDAR scans. This allows the annotator to project the camera image onto the 3D points (or view them side-by-side) to create a "context-rich" workspace.
This technique changes the labeling process in two specific ways:
- Traffic Signal Recognition: The camera identifies that a light is "Red," while the LiDAR confirms exactly how far away the intersection is.
- Occlusion Management: If a pedestrian walks behind a parked truck, the camera might lose them entirely. However, the LiDAR can often detect their protruding limbs or depth signature, allowing the annotator to maintain a continuous track even when visual data fails.
By fusing these sensors, teams build redundancy. If glare blinds the camera, the LiDAR sees through it. If the LiDAR misses a flat lane line, the camera catches it. This cross-validated ground truth allows the AI to maintain a complete understanding of the scene even when one sensor is compromised.
Polygon and Mask Annotation
The real world is not made of rectangles. Traffic signs are circular, stray animals have organic profiles, and winding roads do not fit neatly into square boxes.
To capture these irregular shapes, annotators utilize polygons and masks.
- Polygons: In this workflow, the annotator clicks a series of points to trace the exact contour of an object (like a car or a lane marker). This vector-based approach creates a tight outline that excludes background pixels.
- Masks (Brush Tools): For more complex surface details like puddles, road damage (cracks and potholes), or scattered debris, annotators often use "brush" tools. This allows them to "paint" over the specific hazard, treating the image like a digital canvas to classify every pixel of the danger zone.
By explicitly separating the "subject" from the "background," these techniques enable the AI to understand the precise geometry of the road and distinguish exactly where the asphalt ends and the soft shoulder begins.
4D Temporal Tracking
A single image can tell you where a car is, but it cannot tell you where it is going. Because driving occurs in time as well as space, annotators must bridge the gap between static frames.
Temporal tracking introduces the fourth dimension: Time. In this workflow, annotators assign a Unique ID to an object (e.g., "Car_001") and track it across hundreds of consecutive frames. Instead of manually drawing a box in every single frame, annotators often use interpolation or model-assisted labeling (i.e. SAM2 for tracking), which marks the object's start and end points, then let software fill in the movement between them.
This ensures the AI understands that the car in Frame 1 is the same vehicle as the car in Frame 100, creating a consistent narrative of motion.
Key applications for this predictive data include:
- Intent Prediction: Distinguishing between a pedestrian standing still on a corner versus one actively walking toward the crosswalk.
- Velocity Estimation: Calculating how fast a neighboring car is accelerating to predict if it will cut in front of the AV.
By transitioning the AI from a system that merely reacts to individual frames to one that anticipates future movement, temporal tracking provides the "defensive driving" intuition required for safe interaction with human drivers.
Core Use Cases of Annotation for Powering AV Perception, Prediction, and Safety
By applying the previously discussed techniques to multi-modal sensor data, engineers enable the following critical capabilities.
Real-Time Object Detection (Perception)
The Goal: An autonomous vehicle must instantaneously identify and classify every agent (vehicles, pedestrians, cyclists) within the environment to enable immediate reaction.
The Role of Annotation: Annotators draw tight bounding boxes around objects across millions of frames. This trains the AI to handle "class imbalance" and ensures it detects a rare object (like a child on a scooter) just as accurately as a common sedan.
Real-World Example: Waymo releases massive datasets containing annotated high-resolution sensor data. By rigorously labeling signal states (Red/Yellow/Green) and temporary road objects, Waymo trains its AI Model to strictly adhere to traffic laws and right-of-way rules, even in complex urban clutter.
Creating a Drivable Area Mapping (Scene Understanding)
The Goal: Before moving, an AV must define the "drivable free space", which is the exact geometry of safe road surface versus dangerous obstacles.
The Role of Annotation: Using masks and polygons, annotators create a digital mask that classifies every pixel (e.g., Road, Curb, Sidewalk). This prevents the AV from clipping a curb during a turn or drifting into a construction zone where lane lines are missing.
Real-World Example: NVIDIA DRIVE utilizes panoptic segmentation, which combines instance segmentation (distinguishing distinct objects like "Car A" from "Car B") with semantic segmentation (classifying background surfaces like "Road" vs. "Grass"). Because the AI understands the scene pixel-by-pixel, it can navigate undefined road edges, such as rural roads without painted lines, by identifying the drivable path based on texture and geometry rather than relying solely on lane markers.
Intent and Behavior Forecasting
The Goal: The system must shift from detection (what is here?) to prediction (what will it do next?).
The Role of Annotation: By using Temporal Tracking (Unique IDs), annotators trace the path of an object over hundreds of frames. This historical data trains the AI to recognize pre-movement cues, such as a car creeping forward at a stop sign or a pedestrian turning their head toward the street.
Real-World Example: “Motion Forecasting (Argoverse)” developed by Argo AI is a benchmark dataset focused specifically on Trajectory Forecasting. It contains annotated tracks of vehicles that allow researchers to train models that predict the probability of an object's location 3–5 seconds into the future.
Environmental Robustness (Multi-Modal Perception)
The Goal: The vehicle must maintain a fault-tolerant view of the world even when specific sensors fail due to blinding sun glare, heavy rain, or pitch darkness.
The Role of Annotation: Sensor Fusion annotations teach the AI to correlate different data streams. Because annotators have verified the labels across both Camera and LiDAR, the AI learns that a "pedestrian" has a specific shape in the point cloud. If the camera is blinded by glare, the AI can rely on that learned LiDAR shape to keep tracking the person.
Real-World Example: The nuScenes Dataset (Motional) is the first dataset to carry a full sensor suite (Camera, Radar, LiDAR) and is the industry standard for training AVs to maintain accurate detection in challenging weather or low-light conditions.
What Platform Can Help You Annotate Data for AV Applications?
Developing perception models for autonomous vehicles isn't just about data volume, it’s about data complexity.
Because success hinges on integrating synchronized sensor streams (camera, LiDAR, radar), traditional 2D annotation tools fall short, as they simply cannot visualize the depth and temporal data required for safe autonomy.
To meet the needs of an AV project, teams need dedicated infrastructure. That is where platforms like CVAT (Computer Vision Annotation Tool) come in, which utilize a specialized architecture designed specifically to handle these multi-sensor workflows.
CVAT directly addresses the high demands of AV annotation through three key capabilities:
- Native 3D Point Cloud Support: Unlike standard image editors, CVAT can render and annotate raw 3D LiDAR data. It supports high-accuracy 3D cuboids, enabling the creation of the spatial ground truth required for real-time object recognition.
- Pixel-Perfect Segmentation: The platform offers advanced polygon and mask labeling tools essential for defining safe operational boundaries. This level of granularity is non-negotiable for generating the detailed masks needed for drivable area mapping.
- Unified Multi-Modal Interface: Perhaps most importantly, CVAT creates a single workspace for all sensor types. It allows annotators to view and label 2D camera images side-by-side with 3D LiDAR scans.
Why This Matters: The critical advantage of a unified interface is alignment. By keeping camera, LiDAR, and radar data in one view, you eliminate the alignment errors inherent in using separate tools.
Bridging the Gap from Prototype to Production
The difference between a research demo and a road-legal autonomous vehicle lies largely in the quality of its ground truth, and reaching that level of safety requires a fundamental shift in how we treat data.
It is no longer enough to simply draw boxes around cars; teams must now engineer unwavering 3D spatial awareness, ensure temporal consistency across long video sequences, and achieve millimeter-perfect synchronization between camera and LiDAR streams.
To graduate your AV system from a promising prototype to a reliable reality, you need infrastructure that is as sophisticated as the models you are building. CVAT provides the specialized environment to break through these bottlenecks with a complete production workflow:
- Complete Manual Toolset: Handle any scenario with a comprehensive suite of tools, including bounding boxes, ellipses, masks, polygons, polylines, skeletons, and 3D cuboids.
- Model-Assisted Pre-Labeling: Accelerate annotation by up to 10x using integrated models like SAM2 and Ultralytics YOLO, connecting to hubs like Roboflow and Hugging Face, or integrating your own custom models via AI agents.
- Advanced QA & Control: Guarantee data integrity with automated QA tools, including ground truth comparison, honeypots for annotator testing, and immediate job feedback loops.
- Granular Team Management: Scale your workforce securely with detailed roles, granular permissions, and a structured projects-tasks-jobs logic that keeps large-scale operations organized.
- Deep Analytics: Optimize performance with real-time insights into annotator speed, quality metrics, and dataset progress.
If your team is currently bottlenecked by the challenges of sensor fusion or 3D geometry, CVAT offers the specialized environment you need to break through.
CVAT Online lets you get started in the browser without installing or managing infrastructure. The hosted platform supports 2D images, video, and 3D point clouds, so your team can begin annotating mixed sensor data right away while you evaluate your workflows.
CVAT Enterprise is designed for teams running annotation at scale. It adds dedicated support, enterprise security options such as SSO/LDAP, and collaboration and reporting features that help large production teams monitor quality and throughput.




.svg)
.png)

.png)









.png)