


Audio annotation is the silent engine behind the way we live and work today. While much of the public headlines focus on generative text applications, voice technology has quietly become the primary interface for millions of users.
According to Fortune Business Insights, 153.5 million people in the U.S. alone used a voice assistant, and roughly one in three adults owned a dedicated smart speaker.
But behind every seamless "Hey Siri" or "Alexa, play music" is a massive amount of processed data. To understand how these systems actually "hear" and interpret human speech, we first need to define the process itself.
What is Audio Annotation?
Audio annotation is a form of data annotation that involves labeling or transcribing audio data to train machine learning models. Unlike text data, which is already structured into readable characters and words, raw audio is an unstructured waveform.
Just as computer vision (CV) models require bounding boxes to understand pixels, audio models learn by processing metadata and timestamps assigned by human annotators to interpret auditory signals.
In this sense, audio annotation mirrors the complexity of visual data. While CVAT users are accustomed to identifying objects within a spatial coordinate system (like a polygon on an image), audio annotation requires identifying and marking exactly when a sound begins and ends on a timeline.
These labels may include spoken words, speaker identification, background noise classification, emotion tags, or acoustic events.
By aligning sounds with precise time markers, audio data annotation transforms continuous audio files into structured datasets that models can reliably analyze and learn from.
What Tools & Applications Are Used for Audio Annotation?
Audio annotation tools vary widely in scope and capability. Some prioritize flexibility and customization, while others are built for enterprise scale or research grade precision.
The right choice depends on your data volume, accuracy requirements, compliance needs, and whether your use case involves standalone audio or synchronized multi modal inputs.
Below is a structured comparison of the primary tool categories.
Open Source and Community Platforms
Open source annotation platforms provide full transparency and control over data workflows. Teams can self host these tools, customize interfaces, and integrate them directly into internal machine learning pipelines. Their flexibility makes them ideal for startups, research labs, or privacy focused organizations that cannot rely on third party data vendors.
These tools excel when bespoke workflows are required, such as unique labeling taxonomies or domain specific speech datasets. However, they often require in-house engineering resources to maintain and scale effectively.
Enterprise and Commercial Data Engines
Enterprise platforms are designed for high volume annotation and operational scale. They combine workforce orchestration, quality assurance frameworks, compliance controls, and active learning capabilities to accelerate model training cycles.
These systems often include model in the loop feedback, automated pre labeling, and advanced analytics dashboards. They are commonly used in large scale speech recognition, conversational AI, call center intelligence, and automotive voice systems where throughput, consistency, and governance are critical.
Academic and Specialized Research Tools
Academic tools such as ELAN and Praat prioritize precision over scale. They provide advanced waveform visualization, phonetic segmentation, and acoustic measurement capabilities required for linguistic or scientific research.
These platforms are particularly valuable in speech pathology, language preservation, phoneme level modeling, and forensic audio studies. While they may not support enterprise scale workforce management, they offer unmatched control for micro level analysis and experimental research environments.
Understanding the Five Main Types of Audio Annotation Techniques
Different applications require different levels of annotation depth. Some models only need high level categorization, while others require millisecond precision and contextual tagging. Below are the five primary types of audio annotation and how they support modern AI systems.
Audio Transcription
Audio transcription converts spoken language into written text, forming the foundation of most speech recognition systems. By turning audio into structured text data, models can be trained to recognize vocabulary, accents, and linguistic patterns.
There are two primary approaches: verbatim and non verbatim transcription. Verbatim captures every spoken word, filler, pause, and hesitation. Non verbatim focuses on cleaned, readable text by removing fillers and correcting minor speech irregularities.
Key distinctions include:
- Verbatim transcription preserves fillers, false starts, and pauses for deeper linguistic or legal analysis
- Non verbatim transcription improves readability for business intelligence and conversational AI training
- Time stamped transcripts allow alignment between text and audio for improved model accuracy
The choice between these formats depends on the end application. Legal, compliance, and research use cases often require verbatim precision, while virtual assistants and enterprise analytics may benefit from cleaner transcripts.
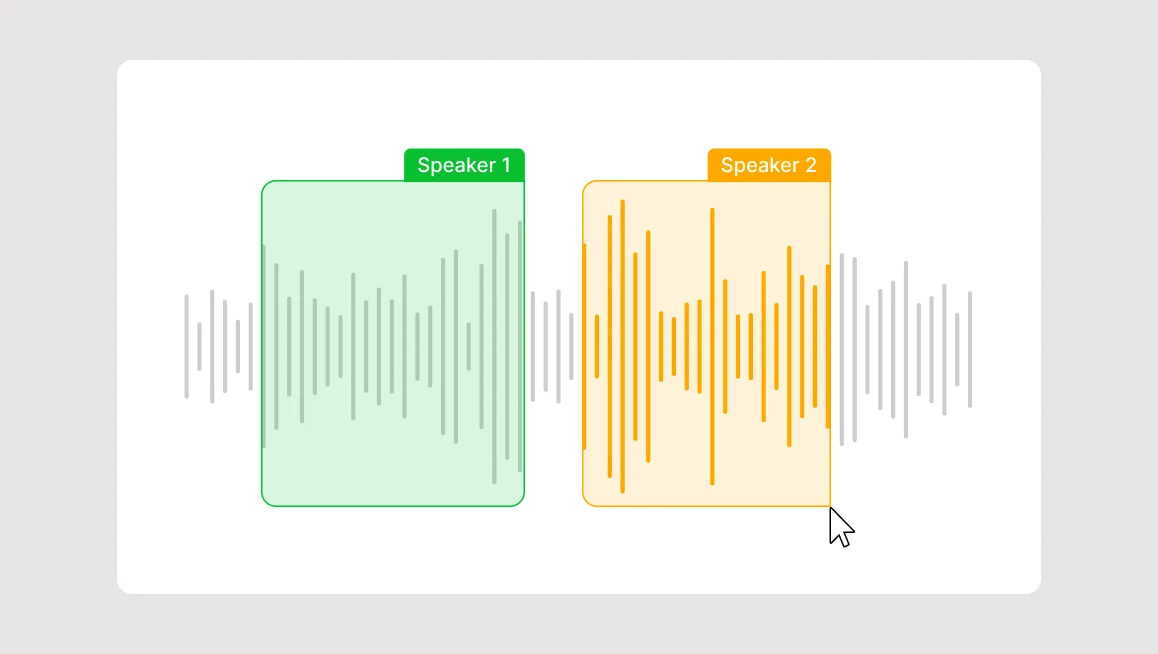
Speech Tagging / Speaker Diarization
Speech tagging, also known as diarization, identifies who is speaking and when they are speaking. In multi speaker audio recordings, simply transcribing words is not enough. Models must distinguish between speakers to understand conversational flow.
Diarization segments audio into speaker specific intervals, assigning labels such as Speaker 1 or Agent versus Customer. This structure enables downstream analytics and conversational intelligence.
Critical components of diarization include:
- Speaker boundary detection to segment conversation turns
- Unique speaker labeling for identity tracking
- Overlapping speech detection in dynamic discussions
This annotation type is essential in meetings, interviews, call centers, podcasts, and legal recordings where speaker context directly affects interpretation and decision making.
Audio Classification
Audio classification assigns a single label to an entire audio clip. Rather than analyzing each moment individually, this approach categorizes the dominant content within the recording.
It is typically used when high level understanding is sufficient, such as determining whether a clip contains speech, music, silence, or environmental noise.
Common classification labels include:
- Human speech
- Background noise
- Music
- Silence
- Mechanical or environmental sounds
Because it operates at the clip level, audio classification is computationally efficient and well suited for dataset filtering, content moderation, and automated sorting systems.
Sound Event Detection (SED)
Sound event detection goes deeper than classification by identifying specific sounds within a clip and marking their precise start and end times. Instead of labeling the entire file, SED focuses on discrete acoustic events.
This method is critical for systems that must react to real world triggers in real time.
Important SED elements include:
- Timestamped event segmentation
- Multiple event detection within a single recording
- Overlapping sound recognition
- Event frequency and duration measurement
Applications range from smart home systems sounding alarms if glass breaks to autonomous vehicles recognizing sirens or horns. The accuracy of SED directly influences system responsiveness and safety outcomes.
Sentiment and Utterance Analysis
Sentiment and utterance analysis focuses on emotional tone and intent rather than just words. It labels how something is said, not only what is said.
This layer of annotation enhances conversational AI systems by enabling them to respond appropriately to user emotion or frustration.
Key annotation factors include:
- Emotional tone classification such as positive, negative, neutral, or frustrated
- Intent tagging to identify requests, complaints, or inquiries
- Contextual utterance labeling across conversation turns
This type of annotation is widely used in customer service AI, sales enablement tools, and virtual assistants. When done correctly, it improves customer satisfaction by making automated systems feel more responsive and human aware.
Popular Use Cases for Audio Annotation Services
Audio annotation is not confined to voice assistants or transcription apps. It powers consumer devices, enterprise productivity tools, safety systems, and advanced scientific research.
Below are the most impactful application areas and how annotation supports each one.
Smart Consumer Electronics (B2C)

In the consumer market, audio annotation enables devices to interpret voice commands, filter noise, and respond naturally. These systems rely on vast amounts of labeled speech and sound data to function accurately across accents, environments, and use cases.
For example, next generation hearing aids use annotated datasets to distinguish speech from background noise in real time. Another example are smart speakers and home hubs that depend on transcription, wake word detection, and intent tagging to deliver seamless user experiences.
To achieve this level of environmental intelligence, developers require:
- Wake Word & Keyword Spotting: Training devices to ignore ambient chatter and trigger only on specific prompts (e.g., "Hey Siri").
- Acoustic Noise Suppression: Labeling background interference so AI can learn to subtract it from the primary audio feed.
- Linguistic Diversity Labeling: Mapping regional accents and dialects to ensure global accessibility and reduced bias.
- Intent Mapping: Categorizing commands so an audio cue such as "Play music" triggers the correct API action.
Without high quality annotation, these devices struggle in noisy homes, multi speaker settings, or non standard speech patterns.
Communication and Conferencing Productivity (B2B)
Enterprise communication platforms increasingly rely on audio annotation to improve productivity and extract insights from meetings. Annotated speech data allows systems to generate transcripts, summaries, and action items automatically.
Virtual meeting platforms such as Zoom or Microsoft Teams integrate transcription models trained on diarized and time stamped audio, as speaker labeling ensures accurate attribution in collaborative environments.
By applying the following layers, platforms like Zoom or Teams turn raw audio into actionable documentation:
- Speaker Diarization: Segmenting audio by individual voice prints to ensure accurate attribution.
- Time-Aligned Transcription: Synchronizing text precisely with the audio timeline for instant playback and verification.
- Semantic Extraction: Identifying key topics and action items automatically to streamline post-meeting workflows.
- Sentiment Analysis: Tagging tonal shifts to provide meeting intelligence on participant engagement or customer satisfaction.
These capabilities transform raw meeting recordings into searchable, structured business intelligence that improves documentation, compliance, and decision making.
Safety, Security, and Critical Infrastructure

In safety critical environments, audio annotation supports systems that must detect and respond to threats immediately. Precision and reliability are non-negotiable.
Security and monitoring systems use sound event detection to identify alarms, gunshots, glass breaking, or distress signals. In autonomous and assisted driving, vehicles rely on annotated datasets to recognize sirens, horns, and emergency signals within complex soundscapes.
Precision-labeled datasets allow security and automotive systems to recognize:
- Sound Event Detection (SED): Training sensors to identify specific thread sounds like breaking glass, alarms, or gunshots.
- Overlapping Signal Recognition: Distinguishing a siren from a horn or engine noise in complex, urban soundscapes.
- Environmental Classification: Categorizing normal background noise vs. anomalous sounds to reduce false positives in monitoring.
- Real-Time Trigger Labeling: Providing the low-latency training data required for instant automated emergency responses.
In these contexts, annotation quality directly impacts response time, risk mitigation, and human safety.
Industrial, Scientific, and Specialized Research

Beyond commercial applications, audio annotation plays a critical role in advanced research domains. These use cases often require extreme precision and domain specific labeling frameworks.
For example, underwater acoustics and sonar systems depend on annotated marine sound data to detect vessels, wildlife, or environmental changes. In healthcare, acoustic biomarkers are used to analyze coughs, speech patterns, or breathing sounds to support early disease detection and monitoring.
Annotation supports these breakthroughs through:
- Waveform & Frequency Analysis: Identifying acoustic biomarkers in healthcare, such as the specific signature of a cough for early disease detection.
- Bioacoustic Tagging: Mapping underwater sonar or forest soundscapes to track wildlife populations and environmental shifts.
- Micro-Level Segmentation: Isolating millisecond-long sound events for high-precision scientific monitoring.
- Long-Duration Monitoring: Labeling changes in machine hums or environmental patterns over months to predict equipment failure.
These applications highlight the depth of audio annotation’s impact, extending far beyond consumer convenience into scientific discovery and public health advancement.
How Does Audio Annotation Work?
The audio annotation workflow is not a single task, but rather a series of steps that moves from raw data acquisition to validated, production ready training datasets. Each phase directly influences model accuracy, bias mitigation, and real world reliability.
Step 1: Data Collection and Curation
Every strong model begins with representative data. Audio must be collected across diverse recording environments to ensure robustness. A system trained only on quiet office recordings will underperform in noisy streets, moving vehicles, or crowded public spaces.
Technical diversity also matters. Datasets should include varying bitrates and sample rates such as 8kHz for telephony and 44.1kHz for high fidelity recordings. Multiple file formats including WAV, MP3, and FLAC help models generalize across input types.
Key curation considerations include:
- Environmental diversity such as indoor, outdoor, and high noise scenarios
- Technical variation across sample rates and compression formats
- Demographic coverage including accents, dialects, age groups, and speech patterns
- Balanced representation to prevent bias in recognition accuracy
Without careful curation, annotation quality cannot compensate for dataset blind spots.
Step 2: Audio Data Pre Processing
Before annotation begins, raw audio must be standardized and optimized for labeling efficiency. Pre-processing ensures annotators can clearly hear ground truth events without interference.
Noise reduction filters remove persistent hums, static, or mechanical interference. Long recordings such as two hour podcasts are segmented into manageable 5 to 15 second utterances. This reduces cognitive load and prevents annotation tools from lagging under heavy file sizes.
Critical pre processing steps include:
- Background noise filtering while preserving signal integrity
- Segmentation into short, logically grouped clips
- Volume normalization across the dataset
- File integrity validation to remove corrupted samples
This stage improves both annotation accuracy and workflow speed.
Step 3: The Annotation & Audio Labeling Phase
During annotation, human expertise transforms processed audio into structured training data. Increasingly, teams use model assisted pre labeling to accelerate this phase. Pre-trained AI models perform a first pass, generating draft transcripts or event labels that annotators then refine.
Tasks must align with model objectives. Discriminative models require labeled categories such as sound classes, while generative systems rely on high quality transcription and contextual metadata.
Core annotation activities include:
- Reviewing and correcting auto generated labels
- Setting millisecond precise start and end timestamps using waveform visualization
- Capturing speech transcripts or categorical sound attributes
- Tagging contextual metadata such as emotion, speaker role, or acoustic environment
The precision applied here directly shapes model performance in deployment.
Step 4: Quality Control and Validation
Quality control transforms annotated data into production grade datasets. A common approach is consensus validation, where the same clip is assigned to multiple annotators. If labels align, the data is verified. Discrepancies trigger review.
Accuracy is measured quantitatively for transcription tasks using Word Error Rate and Character Error Rate. Manual spot checks often review a random 10 percent of files to detect subtle transcription errors or timestamp drift.
Effective validation frameworks include:
- Overlap consensus strategies for verification
- Quantitative accuracy metrics such as WER and CER
- Randomized secondary reviews
- Immediate job feedback loops that provide real-time assessments after completing a job.
Strong QC processes ensure annotation quality improves continuously rather than degrading over time.
The Main Takeaways to Scale and Future Proof Your Audio Annotation Strategy
Scaling audio annotation successfully requires strategic discipline, not just operational speed. Teams that future proof their approach focus on quality, structure, and adaptability from the outset.
If you are looking to future proof your audio annotation strategy, here is what you need to do:
First, prioritize data fidelity over raw volume. A high quality seed dataset establishes clear labeling standards and reduces compounding errors as you scale. Clean segmentation, balanced representation, and strict early quality control matter far more than rushing to annotate thousands of inconsistent clips.
Second, increase annotation density. Modern AI systems demand richer metadata beyond simple tags. Capturing attributes such as pitch, speaker prosody, acoustic environment, and emotional tone enables models to become more context aware and resilient in real world scenarios.
Third, start small and iterate. A focused pilot project allows you to define clear annotation guidelines, validate QC thresholds, and stress test tool configurations before committing to full production.
Finally, unify your multi modal workflows. As AI becomes more conversational and context driven, synchronizing audio with video and image data is increasingly critical. Platforms such as CVAT enable precise alignment across modalities, strengthening dataset consistency and model performance.
To wrap things up, audio annotation is no longer a back end task. It is strategic infrastructure. And the organizations that combine high fidelity labeling, layered metadata, and scalable tooling will build AI systems capable of understanding sound with true contextual intelligence.
Additional Resources
If you are looking to accelerate development or benchmark your systems, public datasets and pre-trained models can provide a strong starting point.
Below is a curated overview of widely used datasets and models in the audio AI ecosystem.
Audio Datasets
- Hugging Face ESB
- LibriSpeech
- Common Voice
- VoxPopuli
- Artie
- FLEURS (Flores 101)
- ChiMe-n
- CORAAL
- AMI IHM, AMI SDM1
- Switchboard
- CallHome
- WSJ (devkit)
Models
- OpenAI Whisper
- NVIDIA Nemotron (Parakeet)
- Google MedASR
- Pyannote speaker diarisation (reidentification)
- Silero VAD





.svg)
.png)

.png)









.png)