


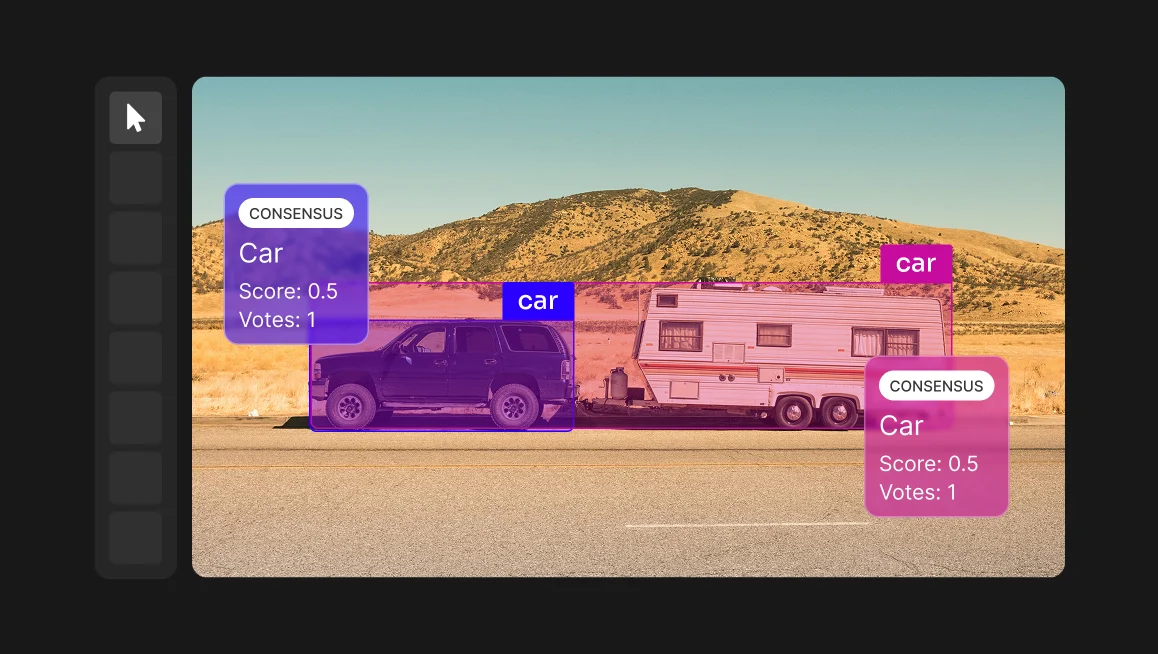
Every machine learning model inherits the judgment of the people who labeled its training data. And when those people agree, the model learns a clean signal. But when they quietly disagree, the model learns the confusion and carries that confusion into production.
This is not a small problem either. In fact, Gartner estimates that poor data quality costs organizations an average of $12.9 million per year and predicts that through 2026, organizations will abandon 60% of AI projects for lack of AI-ready data.
Plenty of that comes down to missing or messy data. But some of it traces back to a quieter and far more underestimated risk: human subjectivity in the labels themselves. Because even if you show the same image to two skilled annotators, they will not always draw the same box, pick the same class, or resolve the same edge case the same way. Those disagreements are normal, but left unmanaged, they can become noise baked into your training data.
Consensus turns that disagreement into something useful. It is a systematic way to collect multiple opinions on the same data, measure how much they agree, and reconcile them into a label you can trust. Used well, it is one of the most effective tools for building reliable training data. Used carelessly, it triples your costs and tells you very little.
This article covers what consensus actually does, where it pays off, where it quietly wastes money, and the mistakes that show up again and again in real pipelines, with input from a core CVAT developer on what teams get wrong.
What Is Consensus in Data Labeling?
Consensus is a method for evaluating and reconciling disagreement between annotators to produce a single, more reliable label.
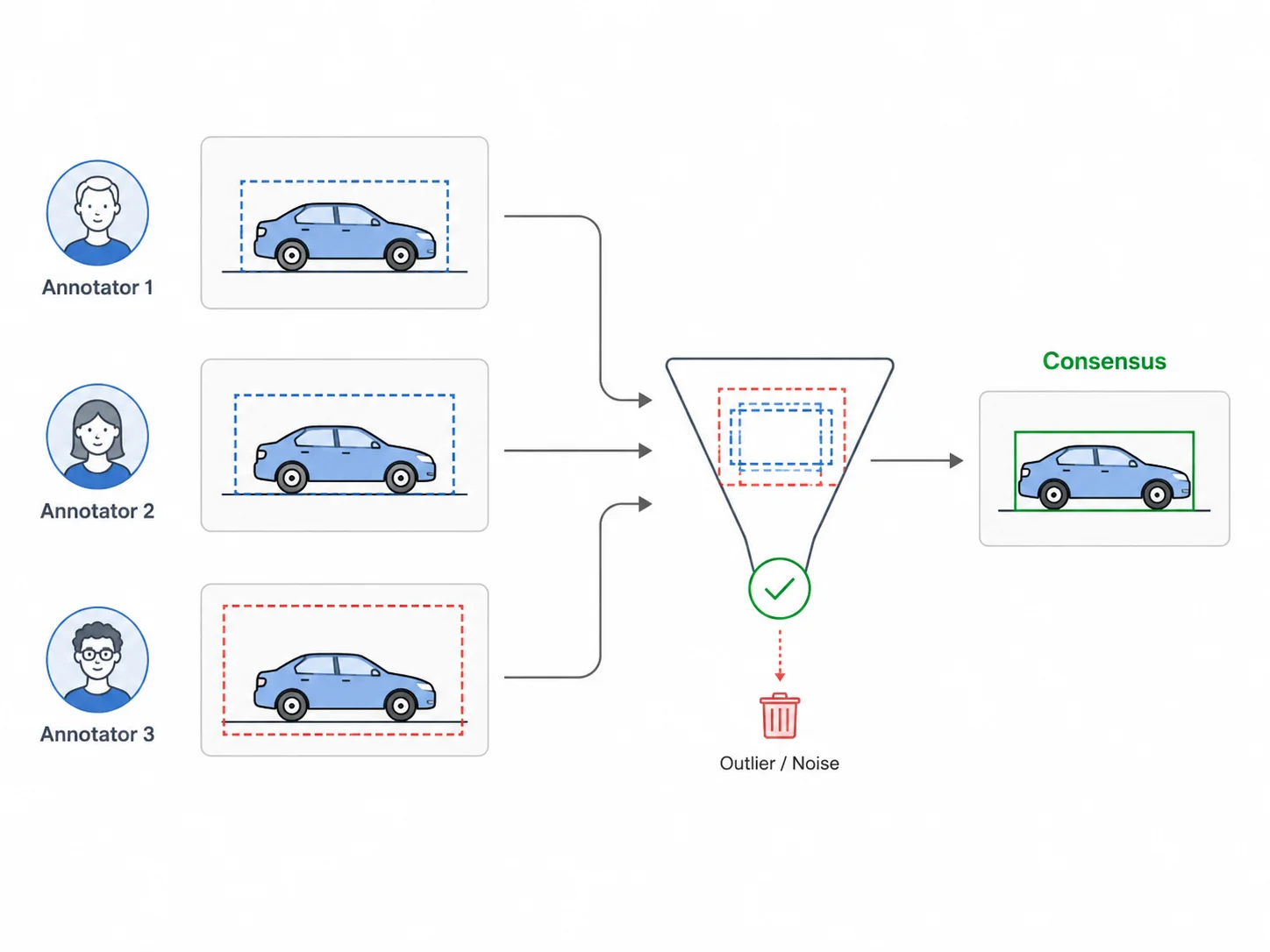
Pretend you asked a room full of people a question and took the most popular answer. If the question is meaningful and the voters are independent, the crowd's combined answer tends to be more accurate than any one person's.
In data labelling, instead of asking a question, each image is labeled several times, usually by different people, and the separate opinions are compared and merged.
The payoff is that consensus filters out the noise, the outliers, and the personal bias that any single annotator introduces. What survives is the most representative version of the label.
How Consensus Labeling Works

The workflow is straightforward in shape, even if the details get nuanced.
- The same asset is assigned to multiple annotators who label it independently, with no visibility into each other's work.
- Each pair of annotations is compared using a similarity measure appropriate to the annotation type. Matches from different annotation sources are aggregated into clusters.
- A resolution method, e.g. majority voting, merges the separate annotations from each cluster into one result and attaches an agreement score.
- Low-agreement items are handled differently because they are most likely to be ambiguous or incorrect. Depending on the system, that might mean flagging them for human review or discarding them automatically.
The scoring step is where most of the technical subtlety lives, as you cannot compare a segmentation mask the same way you compare a keypoint.
In CVAT's consensus engine, spatial annotations such as bounding boxes and masks are matched using Intersection over Union, while points and skeletons use Object Keypoint Similarity. CVAT exposes just one configurable parameter, which is the minimum overlap threshold for annotations.
Common Consensus Methods
Not every team resolves disagreements the same way. The right method depends on the annotation type and how much you trust your annotators relative to each other.
Most production pipelines combine these. Voting handles the easy majority of cases automatically, and adjudication catches the hard minority that voting leaves unresolved.
The Benefits of Consensus-Based Labeling
Fewer Labeling Errors
Any individual annotator can misread an instruction, miss a small object, or simply have a bad afternoon. Consensus distributes that risk. For an error to survive into the final label, several people have to make the same mistake at the same time, which is far less likely than one person slipping once.
Less Annotator Bias
No annotator is perfectly neutral. People carry assumptions about how tightly to trace a boundary or how to read an ambiguous pose. By drawing from several independent annotators, consensus dilutes any single person's interpretation so it cannot quietly skew the whole dataset.
What to Use Consensus For
Beyond producing cleaner labels, there are a few other applications in which consensus is beneficial.
Building Trustworthy Ground Truth
High-agreement labels make an excellent benchmark. Once you have a set of labels that multiple experts independently confirmed, you have a trustworthy reference for measuring everything else.
This is the foundation for the precision, recall, and accuracy metrics you use to score the rest of your annotators and your model. A weak benchmark makes every downstream quality number meaningless. Because ground truth usually covers only a small slice of a dataset, this is also the most cost-effective place to spend consensus, a point we return to below.
Diagnosing Your Guidelines
When annotators keep disagreeing on the same type of object, that is not a failure. It is a signal. Persistent disagreement on a specific scenario almost always means your labeling guidelines are unclear on that point, which tells you exactly where to rewrite them.
Auditing Annotator Quality
You do not have to run consensus on the entire dataset to learn who your strongest annotators are. Apply it to a random slice of production work and the agreement scores reveal which annotators track the group and which are drifting, giving you a quality read on the whole team for a fraction of the cost of labeling every asset multiple times.
The Tradeoffs: What Consensus Costs You
Consensus is powerful, but it is not free, and pretending otherwise leads to bloated budgets.
Higher annotation costs. Three annotators labeling the same image cost three times as much as one. Across a large dataset, that multiplier adds up fast, and it is the single biggest reason teams cannot apply consensus everywhere.
Slower turnaround. Waiting for multiple submissions, computing agreement scores, and resolving conflicts adds time to every stage of the pipeline. A workflow tuned for speed and one tuned for full consensus are not the same workflow.
Diminishing returns. The quality jump from one annotator to three is large. The jump from three to five is much smaller, while the cost rises in lockstep. Most tasks have a point where adding voters stops buying you meaningful accuracy, and finding that point for your use case is part of the job. Additionally, you don’t have to apply the same consensus everywhere - for instance, you can start with a cheap 3-fold consensus, and request more opinions only where the annotators disagree.
Inside CVAT's Consensus Engine: Notes From a Core Developer
To go a bit further into how consensus fits in a workflow, we asked a few questions to Maxim Zhiltsov, who has spent considerable time building and supporting CVAT's consensus and quality control features.
The first message he wanted to share is to cut against the instinct to run consensus across an entire project.
"Full-scale consensus is expensive, because you pay N times for the annotations. Typically you either apply it to a random portion of regular annotations, or to specific parts of the dataset, such as Ground Truth. And because we use majority voting, there are cases where annotators can cooperate and compromise the method, so it is best used together with some ground-truth-based validation."
— Maxim Zhiltsov, Software Developer, CVAT.ai
That last detail is the kind of thing a docs page rarely mentions. Majority voting assumes voters are independent. If annotators can see or coordinate with each other, the math quietly breaks, and a confident-looking agreement score can mask a shared mistake.
Pairing consensus with ground-truth validation closes that gap, because the ground truth set does not vote and cannot be talked into the wrong answer.
When we asked where teams under-use the feature, his answer was specific.
"I would say teams could use it more often for Ground Truth annotation. That is the pipeline step we actually recommend having."
— Maxim Zhiltsov, Software Developer, CVAT.ai
This is the highest-leverage use of consensus that most teams miss.
Ground truth typically covers only a small slice of a dataset, often around 3%. Applying a three- or five-fold consensus to that slice produces a far more reliable benchmark for roughly 10 to 15% of what full-dataset consensus would cost. You spend a little more on the part of the data that validates everything else, and that small investment makes every downstream quality metric more trustworthy.
Consensus also does not have to compete with automation. Model-assisted pre-labeling and consensus solve different problems and can run together.
"The options are orthogonal and can be used together if desired. A mixture of experts, with several model-based and human-based opinions, is a valid approach."
— Maxim Zhiltsov, Software Developer, CVAT.ai
That framing, treating a model as just another voter in the room. CVAT is not forcing teams down that path, but the building blocks are already in place for a mixture of model and human opinions today.
For a forward-looking team, that is worth prototyping now rather than waiting.
Common Mistakes in Implementing Consensus
Setting Thresholds Without Context
Remember that single overlap threshold from earlier. An IoU threshold of 0.95 will reject almost everything as a disagreement, drowning your reviewers in false conflicts. A threshold of 0.40 will accept almost anything, including genuine errors.
Neither number is right by default. The correct value depends on how complex your objects are and how tight your boundaries need to be, and the only way to find it is to test it on real data and adjust.
Treating Disagreement as Noise Instead of Signal
This is the most common and most expensive mistake. Teams accept the majority vote, move on, and never ask why the annotators split.
Persistent disagreement on specific cases is some of the most valuable information your pipeline produces. It reveals edge cases you did not anticipate, guidelines that need rewriting, or annotators who need retraining. Throwing it away is throwing away the main benefit of running consensus in the first place.
Applying Consensus Uniformly
Running consensus on a simple, unambiguous classification task is a waste. You pay the multiplier and learn almost nothing, because there was never any real disagreement to resolve. Save it for tasks where subjectivity or complexity is genuinely high, and let cheaper checks handle the easy work.
No Clear Adjudication Process
What happens when the vote is evenly split? Without a defined escalation path, a senior reviewer, a domain expert, or at least a documented tie-breaking rule, the workflow stalls on exactly the cases that matter most.
Decide who breaks ties and how before the project starts, not in the middle of a deadline.
Skipping Calibration Sessions
Annotators drift. Interpretations that were aligned in week one slowly diverge by week six. Without regular calibration, where the team reviews shared examples and re-aligns on edge cases, agreement scores can decay even while the dashboard still shows green. Calibration is cheap insurance against slow, invisible quality erosion.
Managing Consensus and Quality Control in Practice
Consensus is one tool in a larger quality assurance system, not a replacement for the rest of it. The strongest pipelines combine automated and manual checks. Automated tools catch systematic errors at scale and flag the suspicious items, while manual review handles the nuanced judgment calls that no rule can encode. You want both, and you want them reinforcing each other.
It also helps to understand how consensus sits alongside the other two mechanisms most teams rely on. Each does a distinct job.
A practical pattern ties all three together. Use consensus to build a rock-solid ground truth set, deploy that set through honeypots to monitor your wider team cheaply, and reserve consensus replica jobs for the genuinely hard slices where voting earns its cost.
The labeling quality control academy lesson covers how these layers fit together.
How CVAT Makes Consensus Easier to Get Right
Consensus is one of the most effective ways to produce reliable training data, but it only delivers value when you apply it deliberately. The goal is not perfect agreement on everything. It is knowing where to invest in agreement and how to act on what the disagreement reveals. Teams that treat disagreement as a signal rather than noise end up with better guidelines, better annotators, and better data.
CVAT is built to support exactly this kind of structured, quality-driven workflow, with consensus, ground truth, honeypots, and analytics integrated into the same labeling environment rather than bolted on afterward.
Here is where to start, depending on where you are.
CVAT Online gives you consensus replica jobs, ground truth validation, honeypots, and team analytics in a browser-based platform trusted by world-leading ML and AI teams. It is the fastest way to run your first consensus workflow today.
CVAT Enterprise adds the security controls, private or air-gapped deployment, and audit traceability that production programs need, so your data never leaves your environment.
CVAT Labeling Services delivers fully managed, high-quality datasets with consensus and ground-truth QA built into the pipeline, for teams that would rather receive production-ready data than build an internal labeling operation.





.svg)
.png)

.png)









.png)