



Annotation quality assurance (QA) is a nuanced discipline involving multiple layers of validation, error detection, and dataset health monitoring — all to make sure the data used to train machine learning models is accurate, consistent, and fit for purpose. Crucially, many root causes of low-quality data stem from ambiguous annotation guidelines, unclear class definitions, insufficient escalation protocols, and annotator errors. A robust annotation QA system aims to address all of these.
In this article we break down the essential layers of annotation quality assurance, explain how each targets a different aspect of the labeling lifecycle, and show how CVAT's built-in features support these layers across diverse annotation tasks.
Understanding Data Annotation Quality Control: A Multi-Layered Framework
Annotation quality assurance is not a single measurement method applied uniformly across all projects. It is better understood as a set of complementary layers, each targeting a different level of quality concern.
Here is a quick overview of what each data annotation QA layer aims to address.
Each layer contributes controlled confidence to the data annotation process. Next, let’s walk through each layer in further detail.
Layer 1: Label-Level QA
Human Review & Manual Oversight
Manual review is the foundational layer of annotation QA that involves subject matter experts or skilled annotators examining samples of labeled data to catch errors that automated systems cannot reliably detect.
The most common types of errors they spot include:
- Contextual misinterpretations.
- Ambiguous class assignments.
- Shape inaccuracies like a bounding box that clips the edge of an object rather than enclosing it fully.
What makes manual review irreplaceable is judgment. Automated checks can tell you whether a box exists or whether a field is filled in, but they cannot detect all possible errors. That requires a human who understands the task, the domain, and the edge cases.
The limitation of manual review is scale. Reviewing every annotation in a large dataset is not practical, which is why it is typically applied to a representative sample rather than the full dataset. It is most effective when used alongside automated methods, catching the errors that rules and metrics miss, while letting automation handle the volume.
Ground Truth-Based Data Quality Validation
Ground truth-based validation is the automated counterpart to manual review of data annotation quality. Where manual review relies on a human expert to spot errors frame by frame, ground truth (GT) validation scales that process by comparing every annotator's output against a pre-annotated reference set, automatically, and at volume.
The core idea is straightforward: a set of frames is annotated with exceptional care and treated as the reference standard. When other human annotators label those same frames as part of their regular work, their results are compared against the reference. The degree of match, which is measured using task-appropriate metrics like Precision, Recall , or Intersection over Union becomes a quality score for that annotator's work.
This approach makes it possible to monitor annotation quality continuously and objectively, without a human reviewer having to inspect every submission manually. It also creates a consistent standard across a team, so quality is measured the same way regardless of who is reviewing.
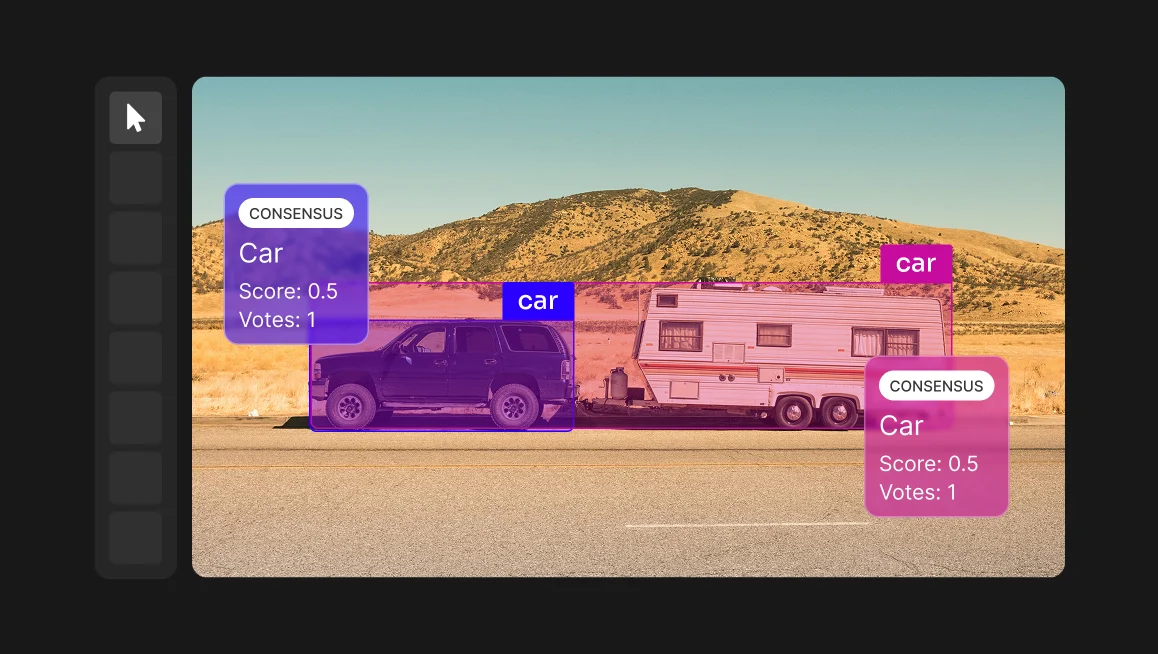
Layer 2: Inter Annotator Agreement and Adjudication

No two people see the world in exactly the same way and that applies to annotation too.
When you ask multiple annotators to label the same image, they will not always produce identical results. One person might draw a bounding box tightly around an object; another might leave more margin. One might classify an ambiguous pose as standing, another as crouching.
These differences are not necessarily mistakes and instead often reflect genuine ambiguity in the data quality or in the labeling guidelines .
This is where inter-annotator consistency comes in, which is the way you can measure how much agreement exists between annotators working on the same data.
A high level of agreement suggests the task is well-defined and the guidelines are clear. A low level of agreement is a signal worth investigating. As it may mean the annotation instructions are ambiguous, the task is inherently subjective, or certain edge cases need better documentation.
Inter-annotator consistency is particularly valuable because it surfaces problems that no single reviewer would catch on their own. If one annotator consistently labels something differently from everyone else, that is useful information. If all annotators disagree on a particular class or scenario, that points to a deeper issue with the task definition itself.
The Adjudication Step
When annotators disagree, whether with each other or against the GT, adjudication is required.
If this happens, an adjudicator (typically a senior expert or project lead) reviews conflicting annotations and produces the final accepted label.
This step is central to consensus-based QA and is often where the most important quality decisions are made.
Layer 3: Dataset-Level Health and Distribution Analysis
An annotated dataset can be full of perfectly labelled images and still produce a biased, brittle, or underperforming model. That is because label correctness and dataset quality are not the same thing.
A model trained on accurate but unbalanced data, where some classes are heavily represented and others barely appear, will learn to favour the majority. A model trained on poor data quality that only captures one lighting condition, one camera angle, or one geographic region will struggle the moment it encounters anything outside that narrow range.
Dataset-level health analysis is the layer of QA that looks at the dataset as a whole rather than at individual annotations. It asks not "is this label correct?" but "does this dataset actually represent the problem we are trying to solve?"
This makes it essential to monitor the statistical health and representativeness of the overall dataset through distribution analysis audits that search datasets for:
- Class completeness: Are all defined classes present in the data?
- Class balance: Are classes represented sufficiently for stable ai model training?
- Scene and condition coverage: Does the data cover varied environments, lighting conditions, weather, camera perspectives, and geographies?
- Annotation completeness: Are annotations consistent and comprehensive across different data segments?
Identifying imbalances early allows teams to update annotation specifications, collect additional data, or adjust sampling strategies, all of which prevent model bias, overfitting, and underfitting.
Layer 4: Automated Rule-Based Validation
Some mistakes do not require a human expert to catch. They can be detected automatically, immediately, and consistently using rules.
This is where rule-based validation comes in, which is the layer of QA that enforces structural and logical correctness in annotations through automated checks .
It acts as a first line of defence, filtering out errors that would otherwise break downstream training pipelines or produce invalid data. This frees your QA team to focus their attention on the errors that actually require judgment.
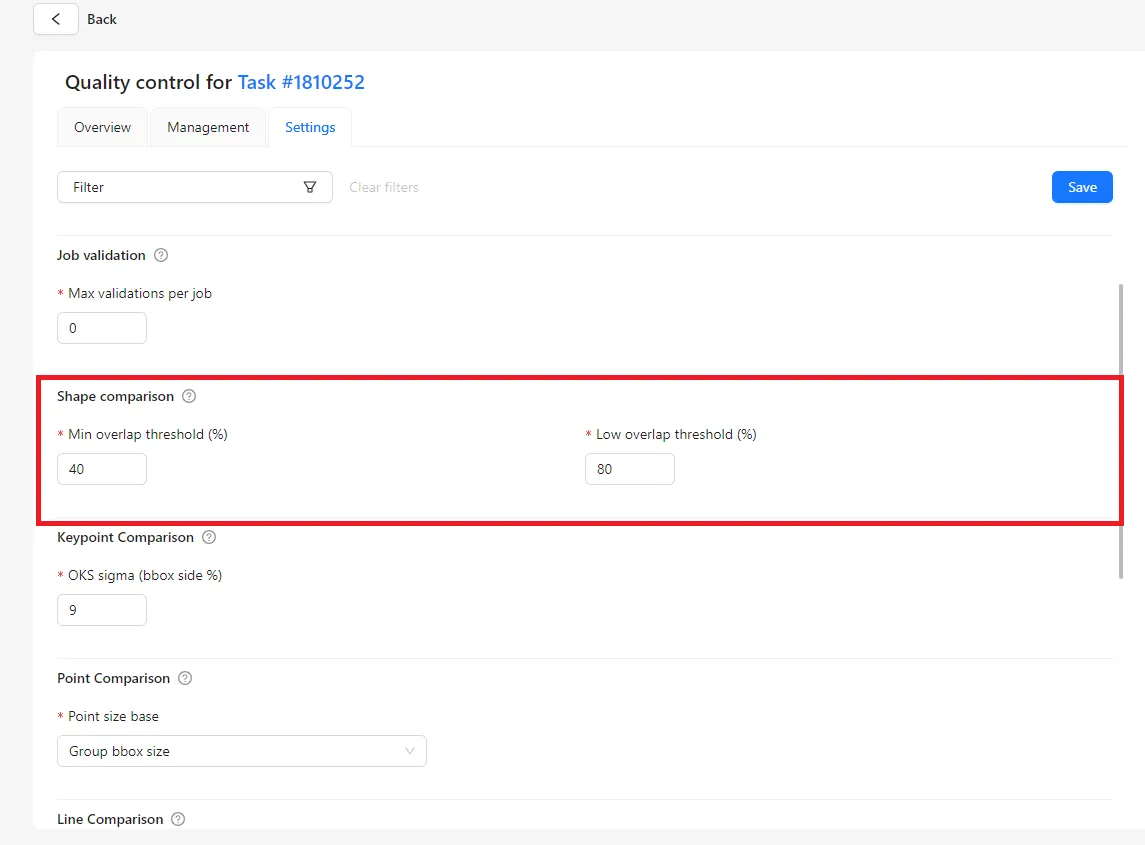
Common examples of validation rules include:
- Bounding boxes must meet a minimum pixel height or area.
- Objects cannot overlap in logically impossible ways (e.g., a car labeled inside a building polygon).
- Attribute values must belong to a defined set.
- Sensitive data or license violations are flagged automatically.
Rule-based validation is best suited for detecting logical errors and critical structural issues. It is worth noting that implementing a comprehensive rule set can be complex, and poorly tuned rules may produce a high volume of false positives that slow down the review process.
Layer 5: Workflow Controls: Thresholds, Sampling, and Rework Policies
Having the right QA tools is only half the equation. The other half is knowing how to use them systematically. Without defined policies and a clear feedback loop, QA becomes inconsistent, as some jobs get reviewed thoroughly while others get waved through. At scale, that inconsistency compounds quickly.
Workflow controls are the operational layer of QA. They are the decisions you make before annotation begins: what score is good enough to accept a job, how much of the dataset needs to be checked to be statistically confident, and what happens when something fails. These policies are what turn individual QA tools into a repeatable, auditable process.
Effective annotation QA requires operational policies that define:
- Pass/fail thresholds: Minimum acceptable annotation accuracy or agreement scores before a job is accepted.
- Sampling strategies: How many and which data points to review or audit to maintain statistical confidence .
- Rework policies: Procedures for handling failed annotations, including re-annotation, annotator retraining, or escalation to a senior reviewer.
Getting the thresholds and sampling rates right takes iteration, as setting them too loose and low-quality work slips through, but setting them too strict and you create unnecessary rework that slows the project down.
Treating these policies as living documents, reviewed and adjusted as the project progresses, is what separates a QA process that scales from one that breaks under pressure.
How Can You Implement Annotation QA with CVAT?
TThe five layers covered above represent the full scope of what a mature annotation QA process needs to address.
However, most teams struggle to implement even two or three of these well, because the tools, workflows, and policies involved are spread across different systems, teams, and stages of the pipeline.
CVAT is built to bring all of that together. Rather than treating QA as something that happens after annotation is finished, CVAT integrates quality controls directly into the labeling environment, so reviewers, annotators, and project managers are working within the same system, against the same standards, in real time.
The table below shows how each CVAT feature maps to the QA layers described in this article.
For more in-depth overview of the CVAT's annotation QA techniques, we also recommend checking this Academy lecture:
Use CVAT to Build a QA Process That Scales
Annotation quality is a continuous process built into every stage of the labeling workflow. The teams that get it right are not the ones with the most reviewers, but the ones with the clearest standards, the right tools, and the discipline to apply them consistently.
That is why the five layers covered in this article exist, to give teams at any scale a practical framework for building annotation quality assurance into their workflow at every step.
If you’re ready to get started, CVAT Online provides access to most of these annotation QA tools including Ground Truth jobs, Honeypots, Consensus workflows, Immediate Job Feedback, and team performance analytics.
For full infrastructure control and enterprise-grade security, CVAT Enterprise offers private, air-gapped deployment with comprehensive audit traceability.
Need a fully managed solution instead? CVAT Data Annotation Services provides end-to-end annotation with built-in QA workflows for teams that need reliable, high-quality training data.
Frequently Asked Questions about Annotation Quality Assurance Techniques
How much ground truth data do I need for training & validation?
The right amount depends on the size of your dataset, how much the data varies, and how complex the annotation task is. As a general rule, 5–15% of your total frames is typically sufficient to get a reliable quality estimate, while keeping the extra annotation overhead manageable.
How do I estimate the validation overhead in a project?
Overhead comes from two places: creating the GT set and running validation as work progresses. GT frames require more careful annotation than regular frames, so factor that cost in upfront.
For ongoing data validation, Ground Truth mode keeps GT frames separate from regular jobs, so the only cost is the initial setup. Honeypots mode mixes GT frames into regular jobs, reducing the number of dedicated GT frames needed but adding a hidden cost per annotation job.
The right choice depends on your resource constraints and how much flexibility you need.
How do I know if my current annotation QA process is effective?
Monitor model performance improvements over time. Persistent mislabelings or unexpected model failures on specific classes or scenarios are strong indicators that QA needs to be strengthened. Error analysis on model predictions is an effective diagnostic tool.
Should I use the same QA approach for every project?
No. Simpler classification tasks may require only manual review or GT checks. Complex segmentation, tracking, or safety-critical labeling tasks benefit from multiple layers: annotator consensus, distribution analysis, and strict rule-based validation.
How do I check whether poor ai model performance is caused by annotation quality?
Perform error analysis on model predictions, then manually review the corresponding training data for those failure cases. A high rate of mislabelings or inconsistent annotations in those samples is a strong signal.
What team size is recommended for consensus-based QA?
Two annotators plus adjudication is a common and practical setup. For some tasks, three-way overlap provides higher confidence, but it increases annotation costs significantly. The right number depends on task complexity, budget, and the criticality of the data.
How is data annotation accuracy measured?
It depends on the task type. For classification, accuracy and precision/recall are standard quality metrics . For object detection and segmentation, Intersection over Union (IoU) measures geometric precision. For keypoints, distance-based tolerances are used. For tracking, temporal consistency and ID switch rates are key indicators.





.svg)
.png)

.png)









.png)