



Ask any ML engineer what keeps them up at night and eventually the conversation lands on data quality. Models get the glory, but data does the quiet, unglamorous work of actually teaching them what's right and what's wrong. So what does it take to build an accurate dataset and how do you know when it's good enough?
The answer lies in establishing a reliable benchmark. This benchmark is known as ground truth data.
Ground truth data is the gold standard against which all other annotations and model predictions are measured. It is the anchor that keeps your machine learning projects grounded in reality. Without it, you are essentially flying blind, hoping that your data is accurate without any objective way to prove it.
In this comprehensive guide, we will explain what ground truth data is, why it is critical for machine learning success, and provide a practical framework for building and maintaining it.
What is a Ground Truth Dataset in Machine Learning?
A ground truth dataset is a meticulously curated collection of data that has been labeled with the highest possible degree of accuracy. It represents the objective reality or the correct answer that your machine learning model is trying to learn and predict.
Think of it as an answer key for a test. When you train a supervised learning model, you feed it data and ask it to make predictions. You then compare those predictions against the ground truth to see how well the model performed. The closer the model's predictions align with the ground truth, the more accurate the model is considered to be.
Ground truth data is not just used for model training and evaluation, it is also essential for annotation quality assurance.
By comparing the work of your human annotators against pre-established ground truth data, you can objectively measure their accuracy, identify areas where they need more training, and ensure consistency across your entire labeling team. This is true whether you are working on a simple image annotation project or a complex video annotation pipeline.
Ground Truth Data vs. Regular Training Data
It is important to distinguish between your general training dataset and your ground truth data. While both consist of labeled data, they serve different purposes and are created with different levels of rigor.
Your general training dataset is the bulk of the data used to teach your model. It needs to be large and diverse, covering as many scenarios and edge cases as possible. While accuracy is important, the sheer volume of data required often means that some minor errors or inconsistencies are inevitable.
Your ground truth data, on the other hand, is typically much smaller, often including just 5% to 15% of your total data.
However, the annotations in this data must be practically flawless. Because of this, they are usually created by your most experienced subject matter experts (SMEs) or senior annotators, who spend significantly more time on each frame to ensure absolute precision.
How to Build a Ground Truth Dataset: Best Practices
Building high-quality ground truth data requires careful planning and execution. It is not something you can rush or treat as an afterthought.
Here is a step-by-step framework for creating a reliable benchmark:
Step 1: Define Clear Annotation Guidelines
Before anyone starts labeling data, you must have crystal-clear, documented annotation guidelines. These guidelines should define exactly what constitutes a correct annotation for every class and scenario in your project.
Your guidelines should cover:
- Class definitions: What exactly is a "car" versus a "truck" or a "van"?
- Annotation types: When should you use a bounding box versus a polygon or a segmentation mask?
- Edge cases: How should annotators handle occluded objects, truncated objects, or objects that are difficult to see?
- Precision requirements: How tight should bounding boxes be? How accurate do polygon boundaries need to be?
Clear guidelines are the foundation of good ground truth data. If your experts cannot agree on the rules, they will not be able to create a consistent benchmark.
Step 2: Select a Representative Sample
Your ground truth data needs to accurately reflect the diversity and complexity of your overall dataset. Do not just pick the easiest images to label. Instead, it is recommended to pick randomly.
A good sampling strategy should include:
- Routine cases: The standard, everyday examples that make up the bulk of your data.
- Edge cases: Rare or unusual scenarios that might confuse your model or your annotators.
- Challenging conditions: Images with poor lighting, bad weather, motion blur, or heavy occlusion.
As a general rule of thumb, aim for your ground truth data to be around 5% to 15% of your total dataset size, depending on the complexity of the task.
Step 3: Assign Your Best Experts
Ground truth annotation is not a task for beginners. It requires deep domain knowledge and a thorough understanding of the project's goals.
Assign your most experienced subject matter experts or senior annotators to create the ground truth data. These individuals should be intimately familiar with the annotation guidelines and capable of making nuanced judgments in ambiguous situations. If you’re annotating the dataset for someone else, additional communications with the dataset owner may be required to resolve ambiguous cases and review the results.
If you do not have in-house experts available, CVAT's Professional Data Annotation Services team can create verified ground truth datasets on your behalf, using annotators with deep domain expertise across computer vision tasks.
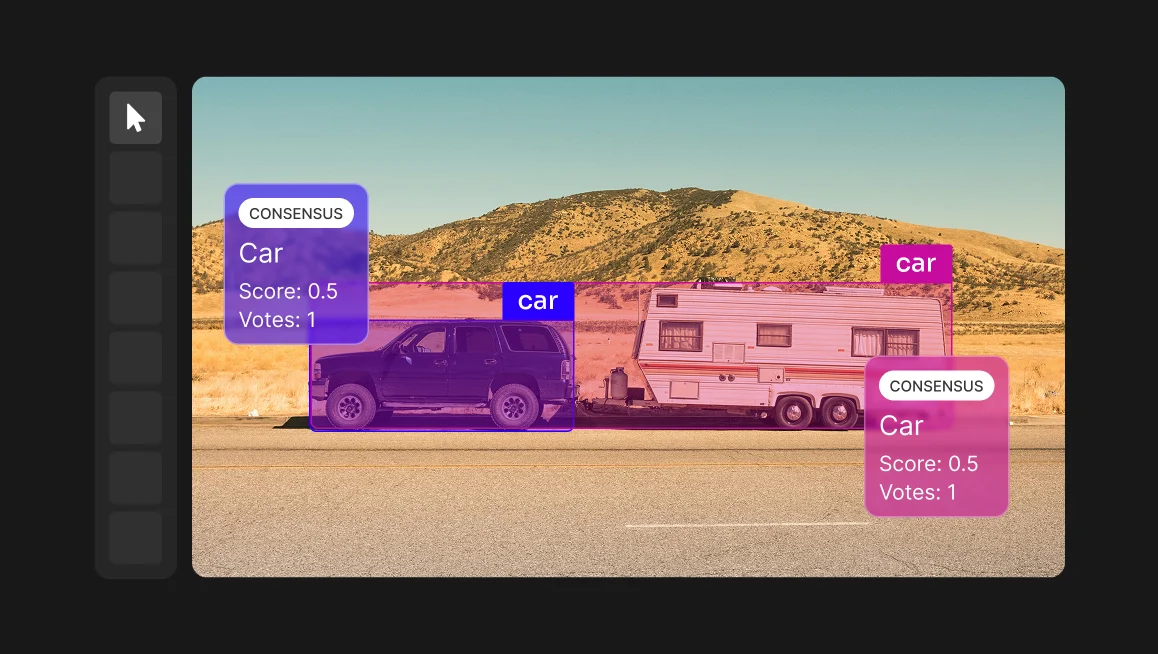
Step 4: Use Consensus and Adjudication
Even experts make mistakes or disagree on edge cases. To ensure the highest possible quality, use a consensus-based approach for your ground truth data.
Have multiple experts annotate the same set of images independently. Then, compare their results. Where they agree, you can be highly confident in the annotation. Where they disagree, an adjudicator (usually the project lead) must review the conflicting annotations and make a final decision.
This process helps eliminate individual bias and ensures a truly objective benchmark.
Step 5: Review and Refine
Once the initial ground truth data is created, review it carefully. Look for any inconsistencies or errors that might have slipped through. It is also a good idea to test the ground truth data against a small sample of your annotators to see if it surfaces any unexpected issues or ambiguities in the guidelines.
How to Maintain Your Ground Truth Benchmark
Ground truth data is not static, it is a living benchmark that must evolve alongside your project. As your model encounters new data in the real world, or as your project requirements change, your ground truth data must be updated to reflect those changes. Here is how you can do that.
1. Monitor for Data Drift
Data drift occurs when the statistical properties of the data your model encounters in production change over time. For example, if you trained a self-driving car model in sunny California, it might struggle when deployed in snowy Michigan.
To effectively combat data drift, you should establish a routine monitoring process that includes:
- Tracking model confidence scores: Flagging production inferences where the model's confidence suddenly drops.
- Analyzing user feedback: Reviewing reports from end-users who encounter incorrect model predictions in the real world.
- Conducting periodic audits: Randomly sampling recent production data to manually verify if the model is still performing as expected.
When you identify new scenarios or edge cases that are not represented in your current ground truth data, you must collect new data, have your experts annotate it, and add it to the benchmark. This continuous feedback loop ensures your model remains accurate even as the real world changes around it.
2. Update Guidelines and Re-annotate
As your project progresses, you will inevitably encounter situations that were not covered in your original annotation guidelines. When this happens, you must update the guidelines to provide clear instructions for these new scenarios.
A structured approach to updating guidelines involves:
- Documenting edge cases: Keeping a running log of ambiguous examples raised by annotators during production.
- Holding consensus meetings: Gathering your experts to review the log and agree on standardized rules for handling the new cases.
- Publishing versioned updates: Releasing the new guidelines with clear change logs so the entire team knows exactly what was modified.
Crucially, whenever you update the guidelines, you must also review your existing ground truth data to ensure it complies with the new rules. This may require re-annotating some or all of the ground truth data to maintain consistency, but it is a necessary step to prevent conflicting signals from confusing your model.
3. Rotate Your Honeypots
If you are using your ground truth data to evaluate annotator performance (a technique often called using honeypots), you must be careful to avoid contamination.
A healthy honeypot rotation strategy requires:
- Setting expiration dates: Retiring ground truth frames from the QA pool after they have been shown to annotators a certain number of times.
- Injecting fresh data: Continuously adding newly verified ground truth frames into the rotation to keep the test set unpredictable.
- Varying difficulty levels: Ensuring the honeypot pool contains a mix of easy, medium, and hard examples to accurately gauge annotator skill.
By regularly rotating new ground truth images into your honeypot pool and retiring older ones, you maintain the integrity of your QA process and ensure that quality scores remain a true reflection of annotator performance.
Implementing Ground Truth QA with CVAT
Managing ground truth data and using it for quality assurance can be a logistical nightmare if you are relying on spreadsheets and manual processes. Thankfully, CVAT provides built-in tools that make it easy to integrate ground truth validation directly into your annotation workflow.
Here is how CVAT helps you build and maintain a quality benchmark:
Ground Truth Jobs
CVAT allows you to designate specific jobs as Ground Truth jobs. These jobs are used to store your verified benchmark annotations. Once a Ground Truth job is configured and completed, CVAT automatically uses it as the standard against which all other annotations in the task are measured.
A GT job in a task can be created anytime manually, or at task creation via Honeypots. This setup enables task supervisors to perform "offline" automatic validation and calculate objective quality scores without disrupting the natural flow of the annotation process.
Honeypots Mode
CVAT's Honeypots mode is a powerful feature for ongoing quality control. In this mode, CVAT randomly mixes frames from your Ground Truth job into the regular annotation jobs assigned to your team at task creation.
Honeypots also rely on GT jobs to manage validation frames and annotations. Similarly to manually-created GT jobs, they allow task supervisors to select validation frames and use them for automatic quality estimation.
The difference is that with Honeypots, the same validation frames can be used multiple times in different annotation jobs. It allows to reduce the amount of validation data needed for quality estimation without sacrificing the objectiveness of the checks performed.
Automated Quality Estimation
With a Ground Truth job in place, either configured explicitly or via honeypots, CVAT can automatically calculate quality metrics for your regular annotation jobs. It compares the annotators' work against the ground truth and generates objective scores based on metrics like Intersection over Union (IoU).
This allows you to monitor team performance continuously without having to manually review every single frame. You can track these metrics over time using CVAT's built-in analytics dashboard.
Immediate Job Feedback
To help annotators improve and catch mistakes early, CVAT offers Immediate Job Feedback. When an annotator finishes a job, CVAT instantly validates their work against the ground truth, if configured. If their quality score falls below a certain threshold, the job is rejected, and the annotator is requested to review their work and fix the errors.
Consensus
For creating the ground truth data itself, or for handling highly complex tasks, CVAT supports Consensus-based annotation. You can assign identical tasks to multiple annotators and then use CVAT's tools to merge their results, measure agreement, and adjudicate conflicts to produce a final, high-confidence ground truth label.
Manual Review
For cases where automated scoring is not sufficient, CVAT also provides a dedicated Manual QA mode. Rather than just fixing individual frame errors, a reviewer can open any annotation job to identify systemic issues. They can compare annotations side-by-side with the ground truth to determine if an issue is repeated across a scene or object category.
This allows the reviewer to decide if there is a worker misunderstanding, an unresolved ambiguity in the annotation specification, or an error in the ground truth annotations themselves. Fixing just specific errors on ground truth frames would compromise the validation method, so this mode focuses on diagnosing the root cause of the conflicts detected by automatic validation.
Take Control of Your Data Quality Today with CVAT
Ground truth data is the bedrock of reliable machine learning. It provides the objective benchmark necessary to train accurate models, evaluate annotator performance, and ensure the overall health of your dataset.
By defining clear guidelines, selecting representative data, and actively monitoring for drift, you can create a benchmark that keeps your AI projects on track.
And the best part is, with the right tools, managing ground truth QA becomes a stress–free process. With CVAT's integrated quality control features, including Ground Truth jobs, Honeypots, and Immediate Feedback, you can automate the validation process, allowing you to scale your annotation efforts without sacrificing quality.
So, are you ready to take control of your data quality? If so:
CVAT Online lets you get started immediately in the browser, with no installation required. It provides access to powerful annotation QA tools including Ground Truth jobs, Honeypots, Consensus workflows, and Immediate Job Feedback so you can begin evaluating your workflows right away.
CVAT Enterprise is built for teams annotating at scale. It adds dedicated support, enterprise security options including SSO and LDAP, and collaboration and reporting features that help large production teams maintain quality and throughput across complex annotation projects.
Or choose CVAT Labeling Services if your team needs production-ready training data without building an annotation operation in-house. With 300+ expert annotators across 12 time zones, CVAT's managed labeling team handles everything from project scoping and annotation to quality assurance and delivery.
Frequently Asked Questions
What Is the Difference Between Ground Truth Data Collection and Regular Data Collection?
Regular data collection focuses on gathering large volumes of raw data to train AI models, where minor errors might be acceptable due to the sheer scale. Ground truth data collection, however, requires a much higher level of precision. It involves human experts meticulously labeling a smaller subset of data to create an objective benchmark.
This benchmark is then used to evaluate model accuracy and ensure the overall quality of the training set.
How Does Labeling Ground Truth Data Improve AI Performance?
Labeling ground truth data provides the definitive "correct answers" that machine learning algorithms need to learn complex patterns. When AI systems are trained against these high-quality datasets, they can make more accurate predictions in real-world scenarios.
Without this rigorous labeling process, models might learn from flawed information, leading to unreliable outputs and poor overall AI performance.
Why Is Human Expertise Necessary for Quality Ground Truth?
While automated tools can help process large volumes of information, human experts are essential for handling edge cases and ambiguous scenarios. Whether it involves natural language processing, speech recognition, or complex image classifications, humans provide the nuanced understanding that machines currently lack.
This human-in-the-loop approach ensures that the resulting ground truth data is reliable enough to serve as a true benchmark.
Can Synthetic Data Replace Real-World Data in a Training Set?
Synthetic data is becoming increasingly useful for augmenting available datasets, especially when historical data is scarce or privacy concerns limit data sharing. However, it cannot entirely replace real-world data. A robust training phase still relies on real-world examples to capture the unpredictable nature of actual environments.
The best strategies often involve combining both types to create comprehensive and diverse training sets.
How Often Should AI Models and Their Ground Truth Datasets Be Updated?
AI applications operate in dynamic environments where conditions frequently change, leading to a phenomenon known as data drift.
To maintain accurate predictions, teams must continuously monitor their AI systems and update their ground truth datasets accordingly. This means regularly collecting new data, refining annotation guidelines, and re-evaluating the model against fresh benchmarks to ensure long-term reliability.





.svg)
.png)

.png)









.png)