



Building a high-performing machine learning model is often compared to constructing a house: the final structure is only as strong as the foundation it sits on. In the context of AI, that foundation is your dataset.
While the industry often focuses heavily on the actual process of data annotation, the reality is the data preparation process is the unsung hero of machine learning.
It is a meticulous, multi-step effort that transforms raw, unstructured information into a refined asset ready for labeling. In fact, studies suggest that data scientists spend up to 80% of their time finding, cleaning, and organizing data.
But while it may be time consuming, proper data preparation for machine learning ensures that your annotation team is working with the right data, in the right format, with the right instructions.
In this comprehensive guide, we will explore the key stages of preparing your dataset, including defining project requirements, sourcing and collecting data, cleaning and pre-processing, and developing detailed labeling guidelines.
Step 1: Define Your Project and Data Requirements
A successful machine learning project requires a solid foundation. Before you even think about data collection or data analysis, you must have a crystal-clear understanding of your project's goals.
Rushing into data gathering without a plan is a guaranteed way to waste time and resources. The data preparation process is inherently iterative, but starting with a strong definition phase minimizes the need to backtrack later.
Clearly Define Your Model’s Objective
Before any data is collected, your team needs to have a precise answer to a simple question: "What problem are we trying to solve?"
Are you building a computer vision model to detect defects on a manufacturing assembly line? Are you training a model for crop detection and classification? The objective dictates everything that follows. If your goal is to automate a visual inspection process, your data preparation efforts will look vastly different than if you are building a predictive text engine.
You must also define the desired outputs of the model and the metrics that will be used to measure its performance. Will you evaluate success based on accuracy, precision, recall, or Intersection over Union (IoU)?
Establishing these benchmarks early ensures that your data preparation efforts are aligned with the ultimate goal of the project. For instance, if high precision is critical (e.g., in medical imaging), your data preparation must prioritize eliminating false positives, which requires exceptionally clean and well-annotated data.
Determine Your Data Needs
Once the objective is clear, you must translate that goal into specific data requirements. This involves answering several critical questions about the data you need to acquire:
- What type of data is needed? Are you working with images, text, audio, video, or sensor data? The format will heavily influence your tooling and storage requirements. For example, preparing a dataset for video annotation requires handling frame rates, keyframes, and temporal consistency, which are not factors in static image annotation.
- What is the estimated volume of data required? Deep learning models typically require massive datasets to achieve high accuracy, while simpler models might perform well with less. You must balance the need for volume with the cost and time required for data collection and labeling.
- What are the essential features, classes, and categories? If you are building a model to recognize vehicles, you need to know if you are just identifying "cars" or if you need to distinguish between sedans, trucks, motorcycles, and bicycles. This level of granularity must be decided before you begin sourcing data.
Step 2: Source and Collect Your Data
With your requirements defined, the next step in the data preparation process is sourcing and collecting the raw data. There are several avenues for acquiring the necessary data, each with its own advantages and challenges.
The goal here is to build a dataset that is not only large enough but also representative of the real-world scenarios your model will encounter.
Leveraging Public Datasets
For many projects, existing public datasets serve as an excellent starting point. These datasets are often cost-effective (or free), readily available, and frequently come pre-labeled.
Popular repositories like Kaggle, Google Dataset Search, and university-hosted collections offer a wealth of information across various domains. Using public data can significantly accelerate your timeline, allowing you to begin training and testing models almost immediately. This is particularly useful during the proof-of-concept phase when you need to validate an idea quickly.
However, there are disadvantages to relying solely on public data. These datasets may not be specific to your project's unique needs, and they often carry inherent biases based on how they were originally collected. If your use case is highly specialized, public data may only serve as a supplementary resource rather than the core of your training set.
Also, keep in mind that public datasets are available to your competitors, meaning they offer no unique competitive advantage.
Navigating Data Licensing and Legal Compliance
When using public datasets, it is critical to understand that "publicly available" does not mean "free to use for any purpose." Ignoring data licensing and legal aspects can lead to severe consequences, including forced model retraining or costly lawsuits.
Before integrating any external dataset into your pipeline, you must verify its license. Many datasets are released under Creative Commons licenses, but these come with specific restrictions. For example, a CC BY-NC license strictly prohibits commercial use, meaning you cannot use that data to train a model for a paid product. Other licenses may require you to open-source your final model (copyleft licenses) or provide attribution to the original creators.
Beyond licensing, you must also consider data privacy laws like GDPR or CCPA. If a public dataset contains personally identifiable information (PII) such as faces, license plates, or medical records, you may be legally required to anonymize that data or obtain explicit consent before using it.
Always consult with legal counsel to ensure your data sourcing strategy complies with both intellectual property rights and privacy regulations.
Creating Your Own Dataset
When public options are not suitable or sufficient, you will need to create a custom dataset. This approach ensures that the data perfectly aligns with your specific use case, though it requires more effort and investment.
Creating a proprietary dataset is often the key differentiator for successful, enterprise-grade machine learning applications. Here are a few ways you can create your own dataset.
Real-World Data Collection
Collecting real-world data involves capturing information directly from the environment. This might include taking photographs, recording video, capturing audio, or gathering sensor readings.
For example, companies developing autonomous vehicles use fleets of cars equipped with LiDAR and high-resolution cameras to capture thousands of hours of driving footage. This data is then processed using specialized tools for 3D point cloud annotation.
When collecting real-world data, it is crucial to emphasize data diversity. You must capture data under different lighting conditions, backgrounds, and angles to ensure your model generalizes well and avoids bias. A model trained only on daytime driving footage will inevitably fail at night.
Synthetic Data Generation
Synthetic data is artificially generated information that mimics real-world data. It is a highly valuable option when real-world data is difficult, expensive, or dangerous to obtain.
For instance, if you are training a model to detect rare manufacturing defects that only occur once in a million units, waiting to collect real images of those defects is impractical. Instead, you can use 3D rendering engines or generative AI to create synthetic images of the defects.
The primary benefit of synthetic data generation is the ability to quickly create large, perfectly labeled datasets, complete with pixel-perfect masks and bounding boxes. This approach allows you to intentionally generate edge cases and challenging scenarios that might be missing from your real-world data collection efforts.
Web Scraping
Web scraping involves using automated tools to gather data from the internet. This can be an efficient way to collect large volumes of text or images.
However, web scraping comes with significant ethical and legal considerations. You must strictly respect website terms of service, copyright laws, and robots.txt files. Scraping personal or proprietary data without permission can lead to severe legal consequences and reputational damage.
Always consult with legal counsel before initiating a large-scale web scraping operation for commercial machine learning purposes.
Step 3: Clean and Pre-process Your Data
Even after collecting raw data, it is rarely ready for immediate use. It is often messy, incomplete, and inconsistent.
That brings us to the next critical step, data cleaning and pre-processing, which refines the raw data into a usable format for labeling and model training. This is where the bulk of the data preparation work occurs.
In fact, Andrej Karpathy, former Head of AI at Tesla, famously refers to this iterative refinement process as "data massaging."
He argues that in the era of modern AI, the most impactful programming no longer happens in the code, but in the meticulous massaging and curation of the training data to isolate the cognitive core that actually helps the model learn.
Data Cleaning Steps
Before you can transform or normalize your data, you must first clean it. This involves several critical tasks designed to remove noise and ensure structural integrity:
- Removing corrupt or unreadable files: When scraping the web or pulling from sensors, some files will inevitably be corrupted. You must run scripts to identify and remove files that cannot be opened or read by your annotation tools.
- Resolving class imbalances: If your dataset contains 10,000 images of cars but only 200 images of motorcycles, your model will be heavily biased toward the majority class. Cleaning involves auditing class distribution and either collecting more data for underrepresented classes or downsampling overrepresented ones.
- Fixing labeling inconsistencies in pre-labeled data: If you are working with a public or third-party dataset that comes pre-labeled, those labels may be inconsistent or incorrect. You must audit a sample of the annotations and correct any errors before using the data as training material.
- Standardizing metadata and file formats: Raw datasets often contain files in mixed formats (e.g., JPEG, PNG, TIFF) or with inconsistent metadata schemas. Standardizing these ensures your pipeline and annotation tooling can process every file without errors.
Key Pre-Processing Tasks
Once you have cleaned the dataset, you can move onto the following pre-processing tasks:
- Handling missing or incomplete data: Datasets often have gaps. You must decide whether to remove the incomplete records entirely or use imputation techniques to fill in the missing values based on statistical estimates. Ignoring missing data can cause algorithms to fail or produce biased results.
- Removing duplicates and irrelevant data: Duplicate entries can skew your model's learning process, causing it to over-index on certain examples. Removing duplicates and filtering out irrelevant data ensures the dataset remains focused and balanced.
- Data normalization and resizing: Machine learning models require consistent inputs. For image data, this means resizing all images to the same dimensions. For numerical data, it involves scaling values to a standard range to prevent features with larger numbers from dominating the model.
- Data augmentation: This technique artificially increases the diversity of your dataset by applying minor alterations to existing data. For images, this might include rotating, flipping, or adjusting the brightness. For audio, it could involve adding background noise or changing the pitch. Augmentation helps the model become more robust and less prone to overfitting.
Once your data is cleaned and pre-processed, you will also need to perform data splitting. This means dividing your dataset into distinct training, validation, and testing sets to properly evaluate your model's performance.
A common split is 80% for training, 10% for validation, and 10% for testing. The test set should be treated as entirely held-out data, never used during training or validation, to provide an unbiased final evaluation of your model's accuracy.
CVAT makes it easy to manage and organize your data at scale. You can import data directly into CVAT and structure it into projects and tasks, keeping your pre-processed data organized and ready for annotation.
Step 4: Develop Clear Labeling Guidelines
The final step before actual annotation begins is developing clear labeling specifications. This step acts as the critical bridge between data preparation and the annotation process itself.
The Importance of Detailed Guidelines
Labeling specifications (or guidelines) are the rulebook for your annotation project. They are essential for ensuring consistency, especially when working with a team of annotators.
A clear, comprehensive rulebook minimizes errors, reduces ambiguity, and saves significant time and money by avoiding rework. Without guidelines, two annotators might label the exact same image in completely different ways, destroying the integrity of your ground truth data.
If you are using a platform like CVAT, you can attach a specification directly to annotation jobs, ensuring that your team always has access to the rules while they work.
What to Include in Your Labeling Guidelines
To be effective, your labeling guidelines must be highly detailed and leave no room for interpretation. They should cover every aspect of the annotation task, from basic definitions to complex edge cases.
Consider including the following elements:
- Class Definitions: Stress the need for clear, unambiguous definitions for each label or category. If your project involves identifying "vehicles," you must explicitly define what qualifies. Does a tractor count? What about a forklift? Clear definitions prevent confusion and ensure that annotators are aligned on the core objectives of the task.
- Annotation Rules: Provide specific rules for how annotations should be applied. For example, if you are using bounding box annotation, how tight should the boxes be? If you are using the brush tool for segmentation, how precise do the pixel boundaries need to be?
- Handling Occlusion and Truncation: You must establish rules for handling objects that are partially obscured (occlusion) or on the edge of the frame (truncation). These rules should dictate whether an occluded object should be labeled as a single entity or split into multiple parts, and how much of an object must be visible to warrant an annotation.
- Edge Case Examples: Real-world data is full of surprises, making it vital to document and provide visual examples for unusual or tricky scenarios. Use a "Good vs. Bad" example format to illustrate correct and incorrect labeling. Showing annotators exactly what not to do is often just as helpful as showing them the correct approach.
For more insights on creating effective rules, you can review our guide on labeling guidelines.
Setting Your Project Up for Success
The journey to a successful machine learning model does not start with labeling; it starts with meticulous data preparation.
By taking the time to define your project requirements, carefully source and collect your data, rigorously clean and pre-process the raw information, and specify clear labeling guidelines, you build a foundation that ensures high-quality annotations and, ultimately, a highly accurate model.
Investing time in these pre-labeling stages is crucial. It prevents costly mistakes down the line and ensures that your data science team can focus on what they do best: building and refining powerful AI solutions.
But even with the right preparation, managing data and annotations at scale quickly becomes complex. This is where having the annotation platform becomes critical. CVAT for instance, can help enforce guidelines, maintain consistency across teams, and streamline the entire workflow from raw data to labeled output.
Are you ready to take control of your data quality?
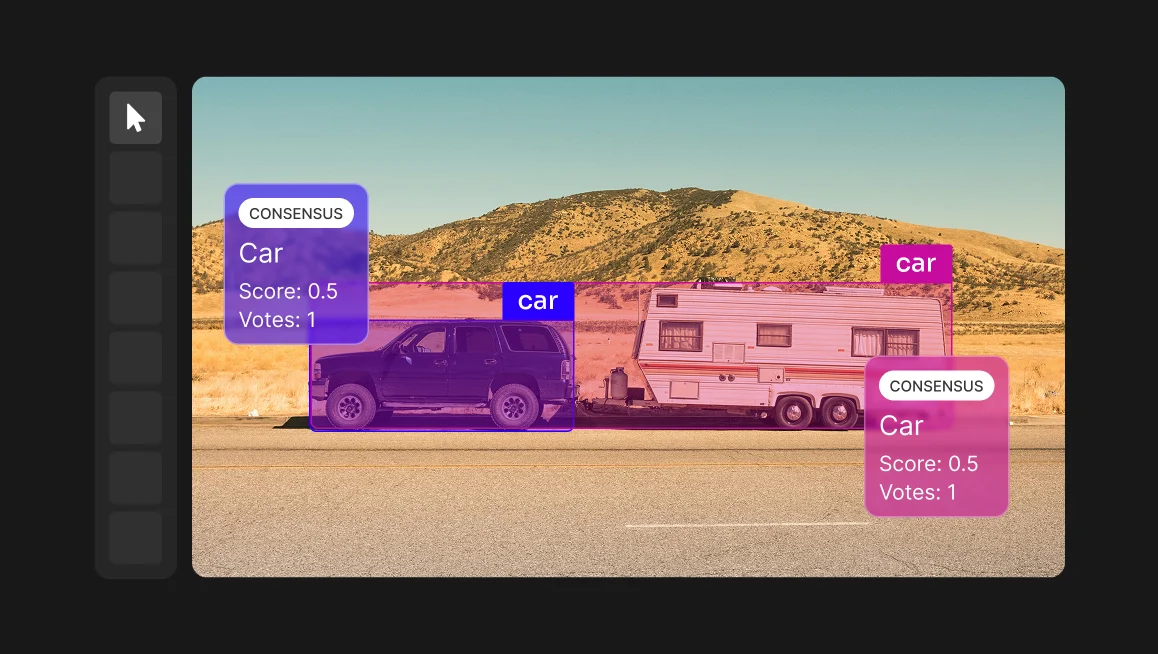
CVAT Online lets you get started immediately in the browser, with no installation required. It provides access to powerful annotation QA tools including Ground Truth jobs, Honeypots, Consensus workflows, and Immediate Job Feedback so you can begin evaluating your workflows right away.
CVAT Enterprise is built for teams annotating at scale. It adds dedicated support, enterprise security options including SSO and LDAP, and collaboration and reporting features that help large production teams maintain quality and throughput across complex annotation projects.
Or, if you'd rather skip the setup entirely, CVAT Labeling Services gives you a fully managed end-to-end solution. From data cleaning and pre-processing to annotation and delivery, CVAT's team of 300+ expert annotators handles anything you need, from data preparation to specialized annotation.
Frequently Asked Questions (FAQ)
What Is the Importance of Data Preparation in the Machine Learning Process?
The importance of data preparation cannot be overstated. In any machine learning process, the quality of your input data directly impacts model accuracy.
That is why proper data prep ensures that ML algorithms can discover useful patterns rather than learning from noise. It is a foundational step for all ML projects, whether you are using supervised learning or unsupervised approaches.
What Are the Key Steps and Common Techniques in Data Preparation?
The key steps typically include data collection, data cleaning, data integration, data transformation, and data reduction.
Common techniques involve handling missing values, normalizing datasets, and performing data validation to ensure quality.
What Role Does Exploratory Data Analysis Play?
Exploratory data analysis (or exploratory analysis) is crucial for understanding your data before modeling.
It involves data exploration and data visualization to uncover trends, spot anomalies, and guide your feature extraction efforts. This step bridges the gap between raw data and actionable analytics.
Where Does Training Data Usually Come From?
Training data can be sourced from various databases, data warehouses, or data lakes. It may consist of structured data (like tables) or unstructured data (like images or text). Effective data management and data security are essential when handling available data from these sources.
What Skills Are Needed for Data Preparation?
Data scientists need a mix of technical skills and domain knowledge. Proficiency in programming languages like Python is essential for manipulating data and building pipelines.
Understanding business intelligence concepts also helps ensure the prepared data aligns with organizational goals.





.svg)
.png)

.png)









.png)